
Бесплатный фрагмент - Записки маркетолога
Чертеж вашего бизнеса

Предисловие
Уважаемый читатель, задача моей книги — показать логику в аналитике данных, которые собирают компании для своей коммерческой деятельности. У книги тоже есть логика. Ее нужно читать последовательно, начиная с первой главы. Если у вас возникнет желание сразу перейти, например, к бизнес-инструментам, — вы рискуете неправильно их понять и ошибочно разработать свои. Поэтому лучше начать с базовых принципов маркетинговых исследований, обратив внимание на возможные ловушки, в том числе и математические. И только пройдя этот путь, можно будет приступать к разработке бизнес-инструментов.
В основу книги легли 10 лет практического опыта работы Маркетингового центра «Эволюция». В книге нет теории, — да простят меня за это читатели, — так сложилось, что я не умею писать про теорию. Мой стиль писательства сформировался во время создания аналитических отчетов для клиентов, когда нужно было решать поставленные задачи. А для решений задач бизнеса нужны только практические решения, которые приносят пользу. В этой книге я хочу подчеркнуть, что все ваши действия должны быть спроецированы на конкретную задачу. И если полученные данные не помогают ее решить, — то либо вы ошиблись на начальном этапе, либо еще не дошли до конца работы. Важно понимать, что не должно быть цифр ради цифр.
Работая с компаниями на региональном уровне, я четко поняла, что бизнесу нужен инструмент от исследователя, который можно сразу использовать для решения поставленных задач. Причем инструмент этот должен быть понятным и легко применимым. Иначе можно доисследоваться до известного анекдота, где сова посоветовала мышкам стать ежиками.
Уважаемый читатель, я искренне надеюсь, что эта книга поможет вам получать правильные необходимые данные и разрабатывать бизнес-инструменты, которые будут максимально эффективны для вашего бизнеса.
Я благодарю всех, кто помогал мне и вдохновлял в процессе написании этой книги. Мой партнер и совладелец Маркетингового центра «Эволюция» — Максим Дигас, — спасибо, что занимался вычиткой и правкой моих замысловатых и запутанных текстов. Ты продумал оформление и подачу книги, работал с дизайнером по переработке сухих графиков в понятный формат. Полностью взял на себя вопросы редактуры и верстки и всю работу, без которой книга не может появиться на свет. Ведь книга — это не только текст, но и визуализация этого текста в понятном для читателя виде. Образ книги разработан Максимом Дигасом. В итоге получилось наше совместное творение.
Спасибо Екатерине Андреевой — твое пожелание написать книгу зародило во мне желание это сделать.
Спасибо Вячеславу Лашкевичу за то, что всегда был рядом и поддерживал меня.
Любовь Лашкевич
Глава 1. Базовые принципы маркетинговых исследований
Базовые принципы важно соблюдать всегда: при разработке инструментария, выделении сегментов, в аналитике, на каждом этапе маркетингового исследования. Нужно регулярно проверять все свои действия — соблюдается ли тот или иной базовый принцип. Как дом стоит на фундаменте, так и любое маркетинговое исследование строится с учетом базовых принципов. И если эти принципы не соблюдаются, то и результаты будут похожи на карточный домик, который в любую секунду может обрушиться, похоронив под собой бизнес.
Принцип однородности исследования
Однородность — равномерность, единообразие, близость, одинаковость, однотипность. Это значит, что собирать данные нужно, используя одну и только одну методику. А проводить анализ — отдельно по выделенным сегментам, которые отвечают конкретным характеристикам. И все полученные по разным сегментам или по разным методикам результаты можно сравнивать, но нельзя смешивать в один анализ.
Рассмотрим пример. Данные по одной задаче можно получить с помощью разных методов. Например, у нас стоит задача оценить стандарты обслуживания клиентов компании Z. Сбор данных проводится при помощи методов «Тайный покупатель» и опроса клиентов. В результате двух исследований мы получаем одни и те же данные — уровень выполнения стандартов обслуживания. Казалось бы, полученные данные можно собрать в одну кучу и проанализировать. Но на самом деле, это не так. Это изначальная ошибка, которая потом приведет к проблемам в бизнесе.
А теперь давайте разберемся, как мы получаем этот результат. Когда мы замеряем уровень стандартов обслуживания с помощью «тайных покупателей», мы получаем оценку, которую «тайный покупатель» сравнивает с известным ему единым стандартом. В случае с опросом, клиенту не известны стандарты обслуживания, принятые в компании Z. Клиент сам для себя определяет некие стандарты, которые — как ему кажется, — должны быть в компании, и сравнивает результат с ними.
То есть в случае с «тайным покупателем» происходит сравнение с реальными, принятыми в компании стандартами. А в случае опроса клиентов происходит сравнение со стандартами, известными только клиенту.
Как показано на рис. 1, данные, полученные с использованием разных методов, пересекаются, но мы не знаем, в какой плоскости, под каким углом, и в каком объеме. Таким образом, при смешивании в один анализ данных из разных методик или методов, мы из плоскости математики и статистики уходим в плоскость интуитивных гаданий.
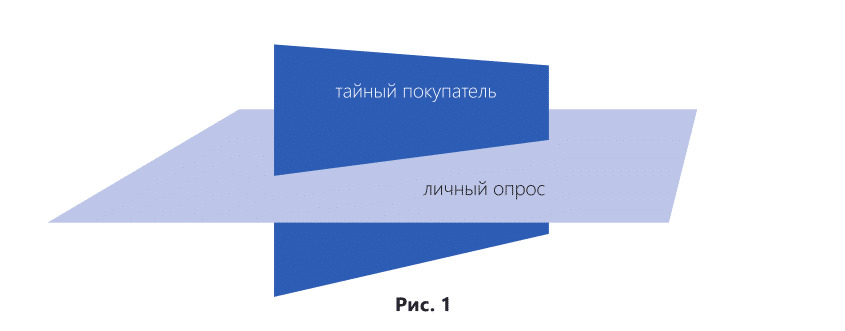
В компании Z провели замеры стандартов обслуживания клиентов и получили следующие интересные данные. Консультантам компании был вменен стандарт «Выявление потребности клиентов». Но клиенты в эту компанию приходят с конкретным запросом и не знают о том, что консультант должен провести с ними определенную работу.
И что мы получаем в результате по данному стандарту обслуживания? «Тайные покупатели» поставили по нему очень низкие оценки, так как им были известны стандарты, принятые в компании. А клиенты компании Z во время опроса поставили высокие оценки, думая, что речь идет об уровне ответа консультанта на заданный ими вопрос.
Если мы эти данные, полученные с помощью разных методик, смешаем в одну кучу, то получим некую непонятную величину, никак не отражающую разницу между восприятием стандартов обслуживания клиентом, и самими стандартами, принятыми в компании. Ведь вполне возможно, что, например, стандарт «Инициативность консультанта» не предусматривает выявления потребностей клиентов, так как клиент приходит с конкретной задачей, и лучше сразу направить силы и время консультантов на процессы, более важные для клиента.
Порой руководство компаний перегружает сотрудников процессами, которые не важны для клиентов, а на значимые процессы у консультантов не остается времени и сил.
Принцип однородности должен соблюдаться, в том числе, и когда вы проводите кабинетные исследования. Когда вы планируете «пройтись» по конкурентам, изучая их работу. В книге принцип однородности исследования будет встречаться часто, и вы увидите примеры, где мы подробно разберем важность соблюдения этого принципа.
Выборка при опросах. «Истина где-то рядом»
Понятие репрезентативности известно уже давно. А калькулятор расчета ошибки выборки доступен любому пользователю Интернета. Тем не менее, часто маркетологи очень вольно обращаются с понятием репрезентативности. Выборку порой назначают (не рассчитывают, а именно назначают) из собственного внутреннего ощущения. Понятие внутренних ощущений в научном труде, (а исследование — это научный труд), сродни вождению автомобиля в нетрезвом виде. Исследователь, который вольно обращается с базовыми принципами, — потенциальный убийца бизнеса. Ведь на основе полученных данных будут построены стратегия и дальнейшие шаги развития компании. И вольное обращение с базовыми принципами построения исследования ведет к весьма вредным для бизнеса последствиям, так как исследование основано на субъективных данных, полученных на основе ощущений одного человека.
Рассуждения о том, стоит ли правильно считать выборку, — то же самое, что обсуждать правила математических вычислений на уровне «нравится — не нравится».
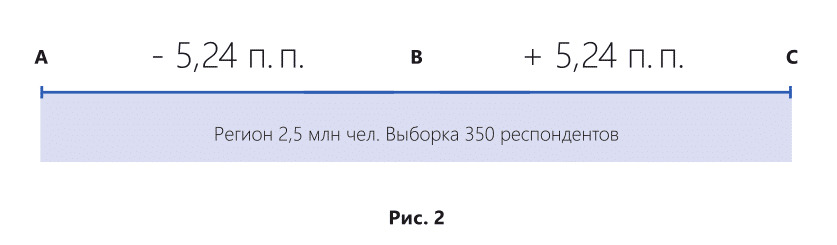
Рассмотрим пример из практики. Специалисты отдела маркетинга компании Z (компания работает в массовом сегменте) решили провести исследование в регионе с населением 2,5 млн человек и посчитали, что 350 респондентов достаточно для получения результатов.
Ошибка выборки в данном случае составит ± 5,24% при расчетах в натуральном выражении. В случае расчета в долях, процентах, ошибка выборки рассчитывается в процентных пунктах (п. п.)
Максимальное отклонение от истины в размере 5,24% возможно только в том случае, если результат исследований находится в точке «В», а истина находится в точке «А» или «С» (рис. 2).
Например, мы вычислили, что доля использования антифриза владельцами автомобилей старше 1997 г. в. составляет 10,6% — это результат. Значит истина находится в диапазоне от 5,36% до 15,84%. Вычисление диапазона при получении результата в процентах:
Нижнее значение диапазона: 10,6% — 5,24 п. п. = 5,36%
Верхнее значение диапазона: 10,6% +5,24 п. п. = 15,84%
При расчетах в натуральном выражении, например, результат равен 100 автовладельцам, истина находится в диапазоне от 95 до 105 автовладельцев. Расчет:
Нижнее значение диапазона:
100 автовладельцев — 5,24% = 95 автовладельцев.
Верхнее значение диапазона:
100 автовладельцев +5,24% = 105 автовладельцев.
Большое это расхождение или маленькое? Возможно ли при таком отклонении делать объективные выводы для эффективной работы бизнеса?
В целом, ошибка допустимая. И с полученными данными можно работать. Но! Дальше — интереснее. Сотрудники маркетингового отдела компании Z принимают следующее решение. Так как исследование по региону происходило в определенных населенных пунктах, то почему бы не провести аналитику полученных данных по каждому населенному пункту?
Такое решение принимают без учета того, что ошибку выборки необходимо пересчитывать заново, уже под конкретный населенный пункт.
Например, в городе с населением 250 тыс. человек было опрошено 20 респондентов. Ошибка выборки в данном случае составит уже ± 21,91% (рис. 3).
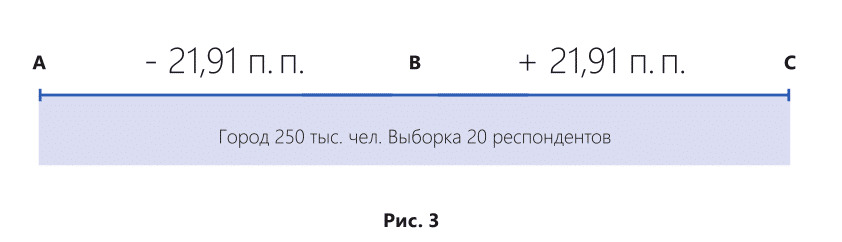
Что мы получаем в итоге. У нас есть результат исследований: доля потребления антифриза владельцев автомобилей старше 1997 г. в. составляет 10,6%. Вычисляем крайние значения, в которых может находиться истина:
Нижнее значение диапазона:
10,6% — 21,91 п. п. = отрицательное число.
Верхнее значение диапазона:
10,6% +21,91 п. п. = 32,51%
Значит истина находится в диапазоне от 0% до 32,51%.
При такой ошибке не стоит опираться на полученные цифры. Невооруженным взглядом видно, что при такой ошибке использование данных для принятия важных управленческих решений может привести к колоссальной ошибке в бизнесе.
Лучше в этой ситуации принять решение интуитивно. Риски будут те же, зато можно сэкономить деньги и потратить их на что-то более нужное — например, на канцелярию.
Глава 2. Сбор данных своими силами
Опасные средние
Достаточно часто в маркетинге используют понятие «средних», — в среднем по рынку в среднем «X» пользователей предпочитают «Y» товаров, и так далее. Понятие «средних» прочно вошло в жизнь бизнеса, на них строятся маркетинг-планы. На средние показатели ориентируются бизнес-стратегии. И мы настолько привыкли к этим средним, что порой не видим опасности, которую они скрывают.
Рассмотрим пример. В среднем по сети показатель уровня клиентского обслуживания составляет 85%. Хорошая цифра. Можно с гордостью эту цифру демонстрировать и спокойно жить до следующего исследования, аналитика которого построена на средних. Только почему-то, несмотря на высокую оценку клиентского обслуживания, проблемы не решаются, и клиенты недовольны. И самое главное — в процессе работы компании возникают вопросы, на которые нет ответов. Исследование, которое выдало столь высокую оценку, в итоге не дает инструмента для ответов на вопросы. Что произошло? А произошло то, что средние величины бывают коварны и таят в себе множество подводных камней. Ориентироваться на средние показатели стоит лишь в том случае, если вы работаете с узкими, четко описанными сегментами.
Давайте посмотрим, как средние величины могут обмануть исследователя, привести его к ошибочным выводам и неправильным управленческим решениям.
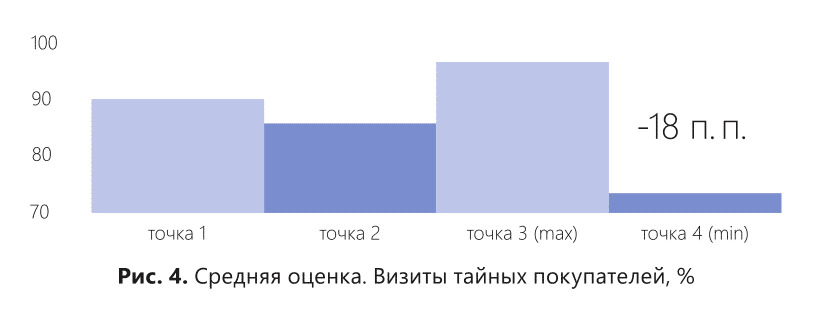
На рис. 4 мы видим, что были проведены исследования уровня клиентского обслуживания на четырех торговых точках. Результаты были рассчитаны с помощью средних величин. Торговая точка 4 показала самые низкие результаты. А остальные три торговые точки показали примерно одинаковые высокие результаты. Итогом такого исследования стало решение руководства премировать торговые точки 1, 2 и 3. А торговой точке 4 объявить взыскание за самый низкий показатель клиентского обслуживания.
Что делать управляющему торговой точки 4 с таким взысканием? Да, уровень клиентского обслуживания — самый низкий по сети, но что конкретно делать — непонятно. Пойти и застрелиться всем коллективом? Ведь результат исследования не дает никакого конкретного инструмента для исправления ситуации.
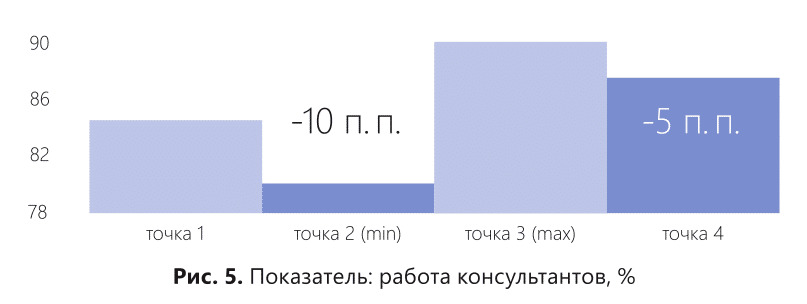
Теперь посмотрим на рис. 5. Здесь в разрезе тех же торговых точек измерены конкретные показатели, которые непосредственно влияют на уровень клиентского обслуживания. Мы видим, что показатель работы консультантов по торговой точке 4 занимает второе место и отстает от лидера всего на 5%. Что же получается? Основываясь на средних величинах уровня клиентского обслуживания, руководство компании объявило взыскание персоналу, который хорошо работает?! Неудивительно, если после подобных действий этот хорошо работающий персонал уйдет из компании.
В то же время, показатель работы консультантов по торговой точке 2 выдает самый низкий результат. И это та торговая точка, персонал которой руководство поощряло на основании средних показателей уровня клиентского обслуживания. Несомненно, персонал, который не очень старался, но при этом получил поощрение, продолжит дальше работать, не особенно усердствуя. И самое опасное, что другие сотрудники сети, наблюдая, как поощряют тех, кто не старается, будут копировать модель «ненапряжного» отношения к работе.
Осталось выяснить, за счет чего так сильно исказились средние величины. Ответ мы найдем на рис. 6. Торговая точка 2 была оборудована лучше всех по сети, там лучший ремонт и новая мебель.
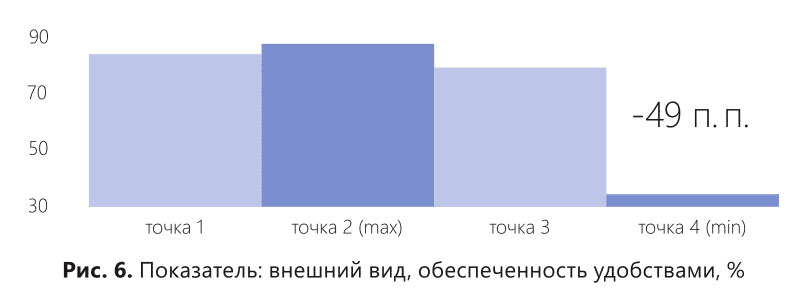
А в торговой точке 4 давно не делали ремонт, там мебель и оборудование старые. Вот и весь секрет успеха и высоких показателей торговой точки 2. Торговая точка 4, не обладая ресурсами торговой точки 2, показывала высокий уровень работы персонала, который действительно заслуживает поощрения. Но опасные средние принижали показатели тех, кто хорошо работал, возвышая тех, кто более халатно относился к своим обязанностям.
Для того, чтобы не попасть в ловушку средних показателей, не стоит «клеить мягкое с круглым». Что происходило в нашем примере: исследователь, собирая данные клиентского обслуживания, вычислял средний показатель, складывая уровень профессионализма персонала с уровнем оборудования торговой точки, и делил эти данные на количество переменных в числителе. С точки зрения математики, вычисления были верны, но по сути они оказались ошибочны и опасны для бизнеса.
Что нужно учитывать в логике анализа данных, чтобы избежать описанной ситуации? Данные, с которыми вы проводите математические операции, должны быть однородными. Это тот самый принцип однородности, который мы разобрали в первой главе. Если вы анализируете уровень клиентского обслуживания, то можете складывать, вычислять средние и делать прочие математические операции только между данными одной группы. Причем вы можете вычислять средний показатель по всей сети, в одной торговой точке, или сравнивать индивидуальные показатели по каждому консультанту.
Но данные из разных групп вы можете только сравнивать. Например, показатели из группы «Уровень проведения консультаций» сравнить с показателями группы «Оформление информационного стенда». При сравнении может оказаться, что в торговой точке высокий уровень проведения консультаций, но менеджеры плохо работают с оформлением информационных стендов, поэтому их общий балл клиентского обслуживания снижен. В этом случае руководитель и персонал торговой точки точно знают, почему они не получили ожидаемых выплат, и что нужно исправить.
Измерение известности. Ошибка в методологии
Одна из задач, которые часто ставит руководство компании перед исследователями — замер известности участников рынка. Замерить известность легко. Достаточно составить небольшую анкету с набором вопросов и провести количественный опрос в соответствии с правильно рассчитанной выборкой.
Так как проводить опрос с двумя вопросами в анкете — непозволительная расточительность, то в анкету, кроме вопроса «Какие компании вам известны?» добавляют еще несколько вопросов, например, «Услугами какой компании вы пользовались?», чтобы в итоге измерить не только известность, но и доли участников рынка.
На примере исследования рынка застройщиков многоэтажных жилых зданий мы разберем ловушки, которые могут встретиться исследователю.
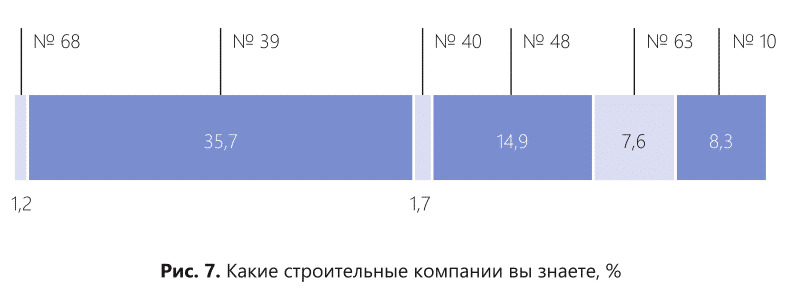
На рис. 7 показаны некоторые результаты замера известности строительных компаний. На вопрос «Какие строительные компании вы знаете?» были названы 72 компании, которые, по мнению респондентов, являются застройщиками многоэтажных жилых зданий.
Из 72 компаний только 4 перешагнули планку известности в 7%. Остальные 66 компаний известны единицам респондентов. Наличие такого большого количества компаний на рынке создает большой информационный шум в голове у клиентов.
Мы видим на рис. 7, что компания №39 обладает наибольшей известностью.
А компания №68 и компания №40 не просто неизвестны, но еще и не проходят по известности порог в 7%. По всем законам статистики и маркетинга, данные компании не могут претендовать на звание «реальный участник рынка». Компании №68 и №40, доля которых не является значимой для массового рынка, показаны на рисунке не случайно. Именно на примере показателей этих компаний мы и разберем ловушку, которая может встретиться исследователю.
Картина становится более интересной, когда мы начинаем сравнивать доли рынка компаний на уровне известности и продаж. Обратите внимание на рис. 8.
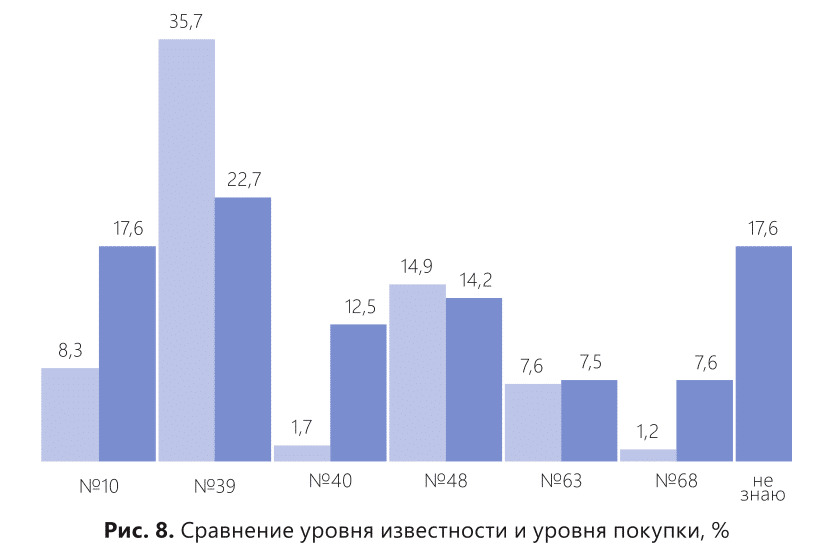
Интересная ситуация складывается с компаниями №40 и №68. Известность у них невысокая, а продажи — на уровне реального участника рынка.
Если мы оставим цифры в таком виде, то рискуем получить вопросы, на которые у нас нет ответов. И скорее всего, несоответствие известности и продаж у компаний №40 и №68 поставит под сомнение все расчеты. Так как существует воронка продаж, которая явно показывает, что известность не может быть меньше продаж.
Итак, что происходит? Ошибка? Да, несомненно, ошибка. Но ошибка была допущена не в расчетах. Она появилась еще на моменте составления инструментария к исследованию.
В опросе участвовали только те, кто в течение года покупал жилье в новостройках. Известность замерялась спонтанно. То есть респондентам предлагалось вспомнить компании, которые, по их мнению, являются застройщиками многоэтажных домов. Пока все идет хорошо. В опросе участвует только конкретно сегментированная группа, которую составляют покупатели. Что происходит дальше?
Для замеров по покупкам предлагалось посмотреть на список строительных компаний. То есть замеры известности проводили спонтанные, а замеры покупок — наведенные (с подсказкой). Именно эта ошибка в методике привела к цифрам, вызывающим вопросы без ответов.
В методике был пропущен блок «Замер наведенной известности». Даже на рынке упакованного печенья наведенная и спонтанная известность сильно отличаются друг от друга. А что говорить про рынок, где люди совершают покупки считанные разы за всю свою жизнь.
Лояльность — это когда клиенты покупают в вашей компании чуть больше, чем у конкурентов.
Пример, который мы сейчас разберем, нужен для того, чтобы при разработке инструментария исследователь извлек из своей работы максимальную пользу для компании. Чтобы в процессе составления анкеты все вопросы были ориентированы на практический результат, важно понимать, какую информацию и в каком объеме вы сможете получить при имеющихся вопросах. Если есть понимание, что в результате сбора данных вы только актуализируете проблему, но не получите ответ на поставленный вопрос, то необходима дальнейшая работа с инструментарием. В примере мы покажем, что вы получите в итоге исследования, если анкета не продумана до конца. И что можно получить, если добавить в нее всего два вопроса.
Итак, другой пример измерения известности и уровня продаж одной из компаний и ее конкурентов. В этом примере вся методика и сбор данных изначально были правильными.
Мы берем в качестве примера рынок, где покупки совершают два-три раза в год. И ситуацию, когда в период кризиса у компании Z произошло снижение продаж.
Возникло несколько версий возникновения этой ситуации:
— люди в целом стали покупать реже
— клиенты ушли к конкурентам
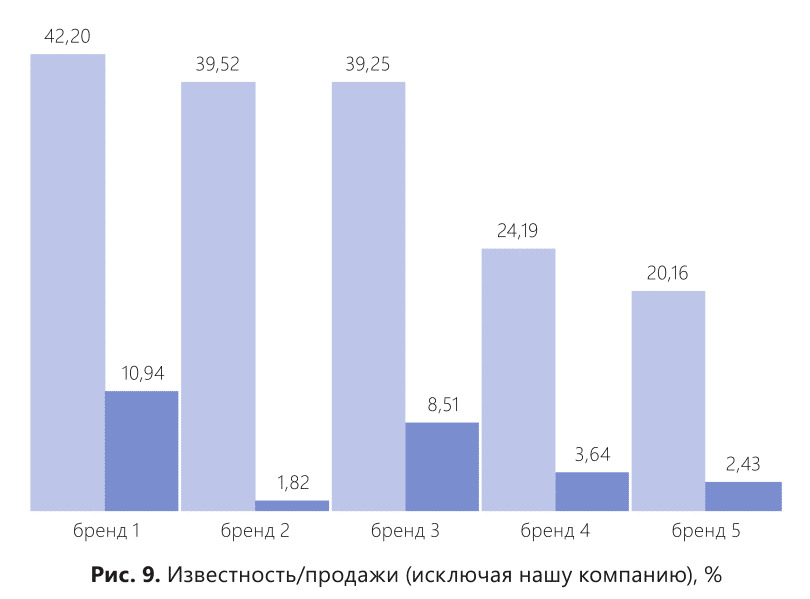
Произведя замеры известности и покупок, компания Z получила следующие данные (рис. 9). Видно, что конкуренты — «Бренды 2, 4 и 5», несмотря на свою большую известность, продают очень мало товара на рынке.
А вот конкуренты «Бренд 1» и «Бренд 3» имеют значимую долю продаж товара на рынке и, соответственно, являются для компании Z реальными конкурентами.
Тем не менее, получив эти цифры (рис. 9), компания Z не получила ответ на главный вопрос и не смогла подтвердить/опровергнуть ни одну из выдвинутых версий.
Затем в анкету включили следующие вопросы: «Сколько раз за год вы покупаете товар „X“?», «Сколько раз в год вы покупали у названных вами конкурентов?»
В результате исследования было выявлено, что большинство респондентов не изменили своей привычке покупать товар «X» более одного раза в год. А те, кто делает вторую или третью покупку товара «X», совершают ее в магазинах конкурентов.
Соответственно, первая гипотеза о том, что люди стали покупать товар реже, не подтвердилась.
Далее было выявлено (табл. 1), что в 2014 году 75,76% клиентов компании Z совершали последующие покупки у конкурента «Бренд 3» и 42,42% клиентов — у конкурента «Бренд 1».

Полученные цифры послужили серьезным основанием для пересмотра стратегии и программы лояльности компании Z. На протяжении года компания Z проводила различные мероприятия по удержанию клиентов.
Что мы получили через год, когда провели такие же замеры? В 2015 году количество клиентов компании Z, которые совершают покупки, в том числе и у конкурентов, уменьшилось в случае с конкурентом «Бренд 3» на 40%, а в случае с конкурентом «Бренд 1» — на 31%.
Глава 3. Глубина маркетинговых исследований
Если полученные данные не могут быть практически применимы в бизнесе — надо копать глубже!
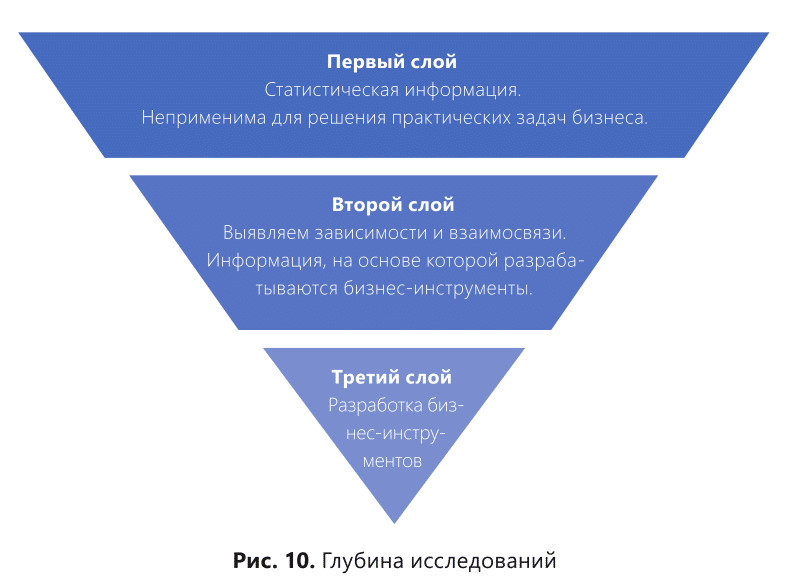
Любое исследование имеет свою глубину. Но не каждое исследование несет в себе информацию, практически применимую в бизнесе. В исследованиях есть три слоя. Первый слой — когда мы получаем статистические данные, которые необходимы для дальнейшей работы исследователя. Второй слой — когда мы выявляем зависимости и взаимосвязи, используя данные, полученные на первом слое. Второй слой также не является конечной точкой в работе. Данные, полученные на первом и втором слое исследования, являются основой для создания бизнес-инструментов, которые разрабатываются уже на третьем слое исследования. Именно результат работы по всей глубине и является практически применимым для бизнеса итогом работы исследователя.
Рис. 10 наглядно демонстрирует, какую пользу для бизнеса может принести то или иное исследование.
Первый слой исследований и анализа данных
Исследования, которые относятся к первому слою — это сбор данных и описание этих данных.
Например, «17% респондентов отмечают, что члены их семей или они сами изучали либо сейчас изучают иностранный язык у репетитора».
17% изучали и изучают. А какой процент из 17% изучает иностранный язык сейчас? И если изучали, то какой процент готов снова заняться изучением иностранного языка? С точки зрения практического применения, данная цифра бессмысленна. Она просто есть и на этом все заканчивается.
На рис. 11 представлена диаграмма количества школ иностранных языков в городе.
Подобные данные являются исключительно информативными. Применить их на практике, например, для разработки стратегии компании, крайне сложно. Если вы являетесь компанией, у которой есть сеть школ, то информация о том, что 151 школа не имеет своей сети, вам нужна исключительно для того, чтобы знать об этом факте.
И если уж обращать внимание на эти данные, то только на десять конкурентов, у которых есть своя сеть. Или, если вы хотите увеличивать свою сеть, то вам понадобятся конкуренты, расположенные в том районе, где вы планируете открываться.
Если вы — компания, которая состоит из одной школы, то вам нужны только те конкуренты, которые находятся в ареале вашего влияния. Так как основной критерий отбора школы — это место расположения, а точнее, близость к дому/школе. Другие районы вам нужны только тогда, когда вы соберетесь открывать еще одну школу именно в этих районах города.
Построение графиков/таблиц, где представлены все компании, декларирующие работу на рынке — неэффективно. Лишняя информация усложняет анализ. Конечно, «кто владеет информацией, тот…» но надо уметь концентрировать свое внимание на той информации, которая необходима для компании в данном месте, в данное время, в текущей ситуации. Чтобы не пришлось «стрелять из пушки по воробьям». Ведь в итоге такого сбора данных вы либо запутаетесь, либо придете к мнению, что исследования — это пустая трата времени и ресурсов, потому что практической пользы от них вы не получили.
Важно понимать, что вам придется пройти первый слой аналитики данных прежде чем приступить ко второму слою. Но данные первого слоя должны быть собраны с учетом задач компании и с учетом всех базовых принципов исследования. Первый слой полученных данных — это не конец исследования, а только начало.
Например, у вас стоит задача «Выведение нового интернет-продукта, с помощью которого пользователи смогут осуществлять определенные платежи».
На первом слое исследования нам необходимо собрать информацию, которая в будущем даст возможность выполнить поставленную задачу. Одно из направлений, которое необходимо изучить — «Уровень тревожности при проведении платежей через Интернет». Так как этот фактор является барьером для использования нашего продукта, можно собрать данные следующим образом, задав вопрос: «Вы готовы осуществлять платежи с помощью Интернета?». В итоге мы бы получили следующие ответы: 75,6% — не готовы, 24,4% — готовы.
Достаточно сложно использовать подобные результаты для решения поставленной задачи. Так как непонятно, при каких условиях 24,4% плательщиков действительно будут пользоваться нашим интернет-продуктом для осуществления платежей. Непонятно также, при каких условиях категория плательщиков, которые не готовы использовать Интернет для платежей, сможет изменить свое мнение.
Один из самых типичных случаев, которые часто возникают в исследовательской практике, — определение факторов выбора клиентами компании/магазина/поставщика. В следующем примере на предварительных фокусированных интервью были выявлены такие факторы. Далее были рассчитаны веса каждого фактора по результатам проведения количественного опроса.
Клиентам компании Z предложили с помощью 10-балльной шкалы оценить важность каждого выявленного фактора. В итоге были получены следующие цифры (табл. 2.).

Что мы видим? Все факторы выбора, по мнению клиентов, важные. Почему выше было сказано, что ситуация типична? Потому что в сознании клиентов есть несколько действительно важных условий выбора. И в состоянии отсутствия изменений для клиента большинство факторов равновесны. Ведь в момент опроса клиент находится в состоянии уже совершенного выбора.
Мы получили данные первого слоя исследования. Предположим, компания Z, основываясь на полученных данных, ставит перед собой задачу, чтобы все факторы выбора получили самый высокий уровень. Это логично — поддерживая все факторы выбора на высоком уровне, компания становится максимально привлекательной для клиента. Но, скорее всего, у компании не хватит ресурсов для того, чтобы при минимальных ценах владеть максимально широкой сетью и самым вышколенным персоналом. Да и надо ли в действительности все факторы выбора поддерживать на самом высоком уровне?
Данные, полученные на первом слое маркетинговых исследований, не дадут нам ответ на этот вопрос. Переходим на второй слой исследований.
Второй слой исследований и анализа данных
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.