
Бесплатный фрагмент - Гуманитарные основы комбинаторных алгоритмов

Гуманитарные основы комбинаторных алгоритмов.
Сборник статей и заметок (информационные науки,
разработка и программирование).
И. Н. Гаврюшин
2023 год
1) ДВА В ШЕСТОЙ СТЕПЕНИ Или один очевидный факт о Книге Перемен
Есть такой памятник древнекитайской письменности, называемый
«Книга Перемен». Подробно о нём можно почитать в Википедии или ином энциклопедическом источнике. Я лишь напомню, что этот текст считается гадательным. Для тех, кто не любит читать энциклопедии: книга состоит из гексаграмм и комментариев к ним. Каждая гексаграмма состоит из палочек двух видов: сплошной «___» и прерывистой «__ __». Палочки символизируют собой начала «Инь» и «Ян». Палочек в каждой гексаграмме очевидно шесть (если вдруг забыли, что означает латинский корень гекс). Об этом памятнике писали многие учёные, неучёные, о нём писали эзотерики, искусствоведы, математики, философы, филологи, обычные блогеры и многое множество интересующихся китайской культурой людей.
Немного истории
Саму книгу на русский язык перевёл востоковед Щуцкий Юлиан Константинович. Книгу изучал знаменитый философ Лейбниц. И, может быть, именно эта книга во многом натолкнула его на разработку двоичной системы счисления. Но на этом исторический обзор я вынужден закончить, так как в общем и целом об этом памятнике и его изучении написано много.
О комбинаторике гексаграмм
Вернёмся непосредственно к самим гексаграммам, число коих в книге 64. Вооружённый микроскопом информатики разум сразу заметит, что число 64 — это степень двойки, иначе говоря двойка в шестой степени. То есть самих гексаграмм в книге 2 в 6 степени.«И какой из этого вывод?» — спросит любознательный читатель. Казалось бы, никакого, но вот только гекскаграммы, символизирующие различные состояния, не повторяются, то есть все 64 гекскаграммы уникальны. И из это следует один примечательный факт: гексаграммы Книги Перемен формально могут рассматриваться в качестве комбинаторного объекта, а именно как размещения с повторением из двух по шесть. Однако компьютерного алгоритма, порождающего последовательности гексаграмм я пока не встречал. Скорее всего, его и не существует. И возможен ли какой-то строгий алгоритм в этом случае?! Я не проверял. При первом рассмотрении последовательности гексаграмм видно, что изменения в них происходят не по чёткому простому математическому принципу, а по каким-то иным законам. В качестве примера возьмём только первые гексаграммы так, как они приведены в оригинальном памятнике: в первой гексаграмме все чёрточки полные, во второй сразу разделённые, в третьей появляются сразу две полные; в четвёртой полные меняют порядок следования, в пятой полных чёрточек уже три, в шестой их четыре и т.д., и т. д. Мы наблюдаем «нарастание и убывание двух начал», их игру во времени.
Заключение
В одной из статей мной была обнаружена замечательная вещь: оказывается существует другой порядок следования гексаграмм, отличный от канонического. Об этом можно посмотреть здесь: synologia, статья называется «К вопросу об истоках последовательности чисел-символов». Но в связи с этим возникает закономерный вопрос: так сколько же возможно порядков следования гекскаграмм?!
Сведущий в вычислении факториалов математик даст довольно точный, но по-своему сногсшибательный ответ. Но будет ли такой ответ верным применительно к самой жизни, состояния которой в общем-то, как мне кажется, и описывает Книга Перемен.
2) Комбинаторные свойства русского текста
«Не комбинатор — не внидет»
Главным фактором, побудившим автора взяться за данную заметку стали занятия переборными алгоритмами, эксперименты с выведением комбинаторных алгоритмов без опоры на учебники и пособия, их программирование.
Результаты практической работы можно найти в сетевом хранилище: на github, репозитарий сименем dcc0. Заметки с примерами алгоритмизации можно посмотреть на habr.com. Для детального изучения вопроса мне понадобилось поработать с 8 классическими алгоритмами перебора множеств и одним достаточно новым алгоритмом порождения суперперестановок (англ. superpermutations). Речь идёт прежде всего об алгоритмах: 1) перестановок (англ. permutations) размещений (англ. arrangements), 3) сочетаний (англ. combinations) 4) разбиений (англ. partitions). Каждый из данных четырёх алгоритмов подразумевает существование этого же алгоритма, но с повторением, именно поэтому алгоритмов получается 8. Ознакомление с данными алгоритмами и комбинаторикой в целом необходимо для выявления и понимания структурной или комбинаторной сложности текстов на русском языке. Читателю предлагается вспомнить, что представляет собой следующие принципы взаимодействия с объектами или операции над ними, именуемые: перестановка, разбиение, сочетание, размещение, композиция.
Я исхожу из следующего посыла: содержание и глубина содержания определяют сложность текста. Органичная сложность русского текста задаёт сложность его математической, комбинаторной структуры, его красоту. Мысль о содержании предопределяющим органическую красоту
выведена мной на основе рассуждений Николая Лосского в работе «Мир как осуществление красоты». В своей работе Николай Лосский критически относится к мысли академика В. Виноградова об отношении «формы и содержания». В его позиции прослеживаются следы идеализма и субъективизма по вопросам эстетики и восприятия. Однако я переношу ранее высказанную мысль с эстетических вопросов на сложность русского текста в структурном аспекте. Таким образом основная идея данной заметки звучит так: органичная сложность содержания задаёт не только красоту, но и определяют структурную сложность текста. В этой связи глубокое понимание содержания текста задаёт предпосылку к глубокому понимаю математики текста, а также развивает способность видеть в тексте то, что не является в тексте математическим. Вопрос о самом определении сочетания органичная сложность не рассматривается.
Слово и фраза имеют комбинаторную структуру и могут изучаться в качестве независимых дефиниций. Слово является вложенной структурной единицей в комбинаторную структуру предложения или фразы. Это «комбинаторика в комбинаторике». Фраза более общая дефиниция относительно слова. Незначительные погрешности во вложенной структуре или изменения могут практически не влиять на создаваемый фразой образ. Слово и фраза — это структура внутри другой структуры; для слова минимальной единицей является буква, для фразы — слово. В отличие от числовой комбинаторики комбинаторика слов естественного языка обнаруживает некоторые законы, которые, говоря математическим языком, можно назвать не в полной мере детерминированными. Например,
В русском слове за согласной буквой часто следует гласная. Помимо комбинаторики букв в слове выделяется также комбинаторика слогов, создаваемая по определенным правилам, в основном правилам фонетики, иногда с отступлением от этих правил, что в математическом аспекте не даёт возможности эти правила детерминировать в полной мере.
Для понимания комбинаторной сложности русских текстов можно попытаться сравнить законы построения предложения в русском и английском языках. Как известно, в английском языке прямой порядок слов, что ограничивает, например, возможность перестановки слов в предложении, хотя поэтическая речь в некоторой степени допускает незначительные перестановки слов. Русский текст лишён этого ограничения почти полностью и допускает практически любой порядок слов в предложении, что в разной степени сказывается на оттенках смысла и значительно дифференцирует русский текст в стилевом плане. Рассмотрение русского текста через призму комбинаторики позволяет изучать его как многомерную связанную структуру, однако при подобном рассмотрении и особенно попытках перенесения комбинаторного взгляда с текста на речь, следует помнить, что некоторые законы и правила письменного текста для устного текста — речи — далеко не всегда работают.
Завершить данную заметку хотел бы эпилогом с рифмой:
Комбинаторика! Как прекрасна ведь она! Но все же разума игра!
Post Scriptum
Для примера возьмём две фразы. «Am I like a god?» и «Am I like a dog?»
Пример того, как можно связать атомизм Демокрита и комбинаторику. Мы переставили буквы в одном слове, осуществили комбинаторный прием — перестановку и получили новый смысл вопроса. Более того, оба вопроса приобрели для нас религиозно-философский смысл. Для самой комбинаторики наше действие, может быть, не имеет смысла, оно похоже на механическое, но оно и результат, который оно даёт, имеет смысл для нас, оно имеет смысл для нас как для волевого, разумного, чувствующего субъекта, иначе говоря для состояния самого нашего духа.
Игра с комбинаторными алгоритмами
3) Путешествие из Москвы в Казань через Санкт-Петербург или процесс разработки алгоритма поиска всех путей
Данный материал публикуется с расчетом на начинающих программистов и неспециалистов…
Однажды вечером после чтения книжек о путешествиях, — кажется, это были знаменитое «Путешествие из Петербурга в Москву» Радищева и «Тарантасъ» Владимира Соллогуба — я сел смотреть лекцию об алгоритме Дейкстры. Смотрел, рисовал что-то на бумажке и нарисовал ориентированный граф. После некоторых размышлений мне стало интересно, как бы я реализовал алгоритм поиска всех путей из одной начальной точки (a) в какую-то другую единственную конечную точку (f) на ориентированном графе. Я уже было начал читать об алгоритмах поиска в глубину и ширину, но мне
подумалось, что интереснее было бы попробовать «изобрести» алгоритм заново, часто ведь при таком подходе можно получить интересную модификацию уже известного алгоритма. Заодно я поставил себе несколько условий: 1) не использовать литературу; 2) использовать нерекурсивный подход; 3) хранить ребра в отдельных массивах, без вложенности. Далее постараюсь описать процесс поиска алгоритма и его реализации, как обычно на PHP.
Сам граф получился такой:
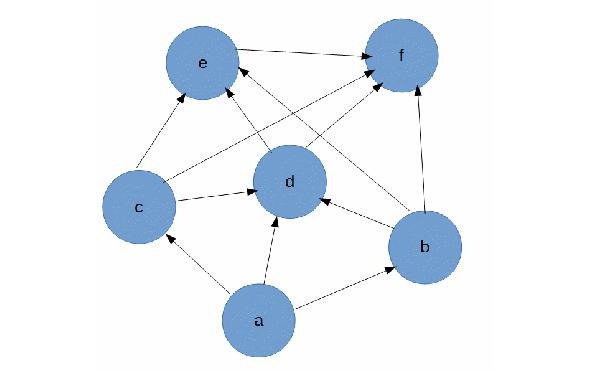
В общем: на входе ориентированный граф с шестью вершинами, задача найти все пути из а в f без рекурсии и с минимальными затратами средств.
Ребра хранятся в нескольких массивах, имя массива — вершина:
$a=array (’b’,’c’,’d’);
$b=array (’d’,’e’,’f’);
$c=array (’d’,’e’,’f’);
$d=array (’e’,’f’);
$e=array (’f’);
Чтобы получить первый путь, я решил пройтись по нулевым индексам каждого массива и склеить их в одну строку х (в этой переменной на каждом этапе будет хранится найденный путь). Но как это сделать с минимальными затратами?! Мне показалось, что самым простым вариантом будет ввести еще один массив — инициализирующий.
В массиве int все элементы, которые есть в графе в обратном порядке.
$int=array (’f’,’e’,’d’,’c’,’b’,’a’);
Тогда получить первый путь очень просто, достаточно пройтись циклом по всем массивам, добавлять в х новое значение с помощью конкатенации, и на каждом этапе использовать элемент из предыдущего массива в качестве указателя на следующий массив.
Этот стиль немного напоминает bash, но код выглядит довольно понятным:
$x=’a’;
$z=$a [0];
while (1) {
$x.=$z;
$z=$ {$z} [0];
if ($z == ’f’) {$x.=$z; break;}
}
И так, мы получили первый путь x=abdef.
Можем вывести его на экран и заняться непосредственно самим алгоритмом, так как все, что было выше, — это только подготовительная часть. По идее от нее можно было бы избавиться, но я ее оставляю и публикую, чтобы был лучше понятен ход мысли.
Выводим на экран первый путь и запускаем первую функцию.
print $x;
print '<br>»;
search_el ($x,$a,$b,$c,$d,$e);
Сам алгоритм фактически сводится к двум циклам, которые вынесены в отдельные функции. Первая функция принимает полученный ранее первый путь x. Далее в цикле осуществляется обход x справа налево. Мы ищем два элемента, один из которых будет работать в качестве указателя на массив, другой (правый, тут только стоит помнить, что массив перевернут) в качестве указателя на элемент массива. С помощью array_search найдем ключ элемента и проверим, есть ли что-нибудь в данном массиве после него. Если есть, то заменим элемент на найденный, но перед этим отрежем хвост (для этого нужен substr). Замену можно организовать и по другому:
function search_el ($x, $a, $b, $c, $d, $e)
{
$j = strlen ($x);
while ($j!= 0)
{
$j — ;
if (isset ($ {$x [$j — 1]}))
$key = array_search ($x [$j], $ {$x [$j — 1]}); if ($ {$x [$j — 1]} [$key +1]!= «»)
{
$x = substr ($x, 0, $j);
$x.= $ {$x [$j — 1]} [$key +1];
new_way_search ($x, $a, $b, $c, $d, $e); break;
}
}
}
Условие с isset нужно, чтобы интерпретатор не выбрасывал
предупреждение. К самому алгоритму оно отношения не имеет. Если никаких элементов в массивах найдено не было, то алгоритм завершится, но если все-таки чудо свершилось, то переходим в новую функцию, суть которой крайне проста — дописать хвост к x, вывести на экран и… «дорисовать восьмерку» или петлю — вернуться в функцию, из которой мы пришли, но уже с новым значением x:
function new_way_search ($x, $a, $b, $c, $d, $e)
{
$z = $x [strlen ($x) — 1];
$z = $ {$z} [0];
while (1)
{
$x.= $z;
if ($x [strlen ($x) — 1] == ’f’) break;
if ($z == ’f’)
{
$x.= $z;
break;
}
$z = $ {$z} [0];
}
echo $x;
echo '<br />»;
search_el ($x, $a, $b, $c, $d, $e);
}
Результат работы алгоритма для графа, что на рисунке выше:
abdef
abdf
abef
abf
acdef
acdf
acef
acf
adef
adf
Дополнение
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.