
Бесплатный фрагмент - Глоссариум по искусственному интеллекту: 2500 терминов
Том 1

От Авторов-составителей
Александр Юрьевич Чесалов,
Власкин Александр Николаевич,
Баканач Матвей Олегович
Эксперты по информационным технологиям и искусственному интеллекту, разработчики программы Центра искусственного интеллекта МГТУ им. Н. Э. Баумана, программы «Искусственный интеллект» и «Глубокая аналитика» проекта «Приоритет 2030» МГТУ им. Н. Э. Баумана в 2021—2022 годах.
Дорогие Друзья и Коллеги!
Авторы составители этой книги посвятили подготовке и созданию данного глоссария (краткого словаря специализированных терминов) два года.
«Пилотная» версия книги была подготовлена всего за восемь месяцев и представлена на на 35-ой Московской международной книжной ярмарке в 2022 году.
В какой-то момент времени книга выросла до восьми ста шестидесяти страниц и нам пришлось подготовить двухтомное издание.
Сейчас мы рады представить Вам первый том книги, который содержит более тысячи двух сот пятидесяти терминов и определений по искусственному интеллекту на русском языке.
Изображение обложки к книге нарисовано в системе генеративного искусственного интеллекта Easy Diffusion.

Почему книга называется «Глоссариум»?
«Glossarium» на латинском языке означает словарь узкоспециализированных терминов.
Идея составления «глоссариев» принадлежит одному из соавторов книги — Александру Чесалову. Первый его опыт в этой области был в составлении глоссария по искусственному интеллекту и информационным технологиям, который он опубликовал в декабре 2021 года. В нем первоначально было всего 400 терминов. Затем, уже в 2022 году, Александр его существенно расширил до более чем 1000 актуальных терминов и определений. Впоследствии он опубликовал целую серию книг, раскрывающих темы четвертой промышленной революции, цифровой экономики, цифрового здравоохранения и многих других.
Идея создания большого глоссария по искусственному интеллекту родилась в начале 2022 года. Авторы пришли к единодушному решению объединить свои усилия и свой опыт последних лет в области искусственного интеллекта, который был подкреплен несколькими знаменательными и судьбоносными событиями.
Несомненно, самое существенное событие, которое произошло несколько ранее в 2021 году — это участие авторов (как экспертов) в Конкурсе, проводимом Аналитическим Центром при Правительстве России по отбору получателей поддержки исследовательских центров в сфере искусственного интеллекта, в том числе в области «сильного» искусственного интеллекта, систем доверенного искусственного интеллекта и этических аспектов применения искусственного интеллекта. Перед нами стояла неординарная и еще на тот момент времени никем не решенная задача создания Центра разработки и внедрения сильного и прикладного искусственного интеллекта МГТУ им. Н. Э. Баумана. Все авторы этой книги приняли самое непосредственное участие в разработке и написании программы и плана мероприятий нового Центра. Подробнее об этой истории можно узнать из книги Александра Чесалова «Как создать центр искусственного интеллекта за 100 дней».
Далее мы приняли участие в Первом международном форуме «Этика искусственного интеллекта: начало доверия», который состоялся 26 октября 2021 года и в рамках которого была организована церемония торжественного подписания Национального кодекса этики искусственного интеллекта, устанавливающего общие этические принципы и стандарты поведения, которыми следует руководствоваться участникам отношений в сфере искусственного интеллекта в своей деятельности. По сути, форум стал первой в России специализированной площадкой, где собралось около полутора тысяч разработчиков и пользователей технологий искусственного интеллекта.
В дополнение ко всему мы не прошли мимо и Международной конференции по искусственному интеллекту и анализу данных AI Journey, в рамках которой 10 ноября 2021 года к подписанию Национального Кодекса этики искусственного интеллекта присоединились лидеры ИТ-рынка. Число спикеров конференции поражало воображение — их было более двухсот, а число онлайн-посещений сайта более сорока миллионов.
Уже в 2022 году мы приняли самое активное участие в Международном военно-техническом форуме «Армия-2022» с докладом «Разработка программно-аппаратных комплексов для решения широкого круга прикладных задач с использованием технологий машинного обучения и доверенного искусственного интеллекта в Оборонно-промышленном комплексе РФ».
Резюмируя всю нашу активную работу за последние пару лет и тот опыт, который был уже накоплен, мы пришли к необходимости систематизировать накопленные знания и изложить их в новой книге, которую вы держите в своих руках.
Мы часто с вами слышим «искусственный интеллект».
Но понимаем ли мы что это такое?
Например, в этой книге мы зафиксировали, что Искусственный интеллект — это компьютерная система, основанная на комплексе научных и инженерных знаний, а также технологий создания интеллектуальных машин, программ, сервисов и приложений, имитирующая мыслительные процессы человека или живых существ, способная с определенной степенью автономности воспринимать информацию, обучаться и принимать решения на основе анализа больших массивов данных, целью создания которой является помощь людям в решении их повседневных рутинных задач.
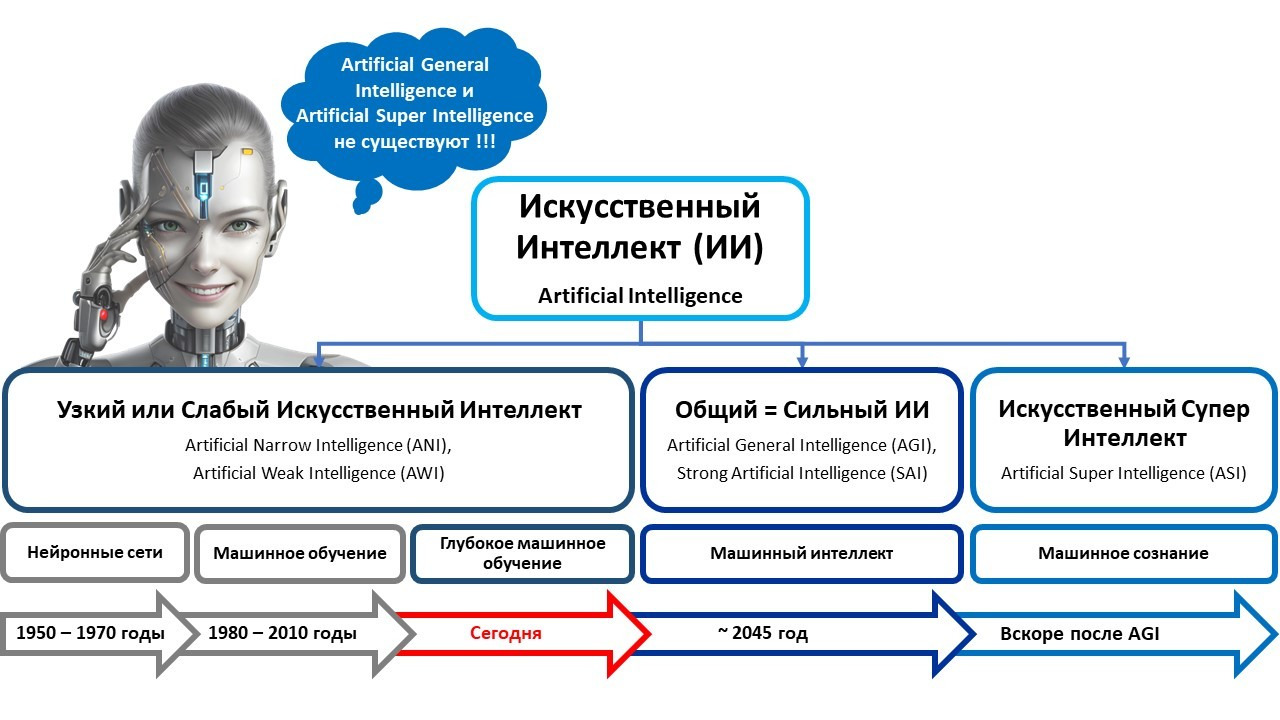
Или, еще один пример.
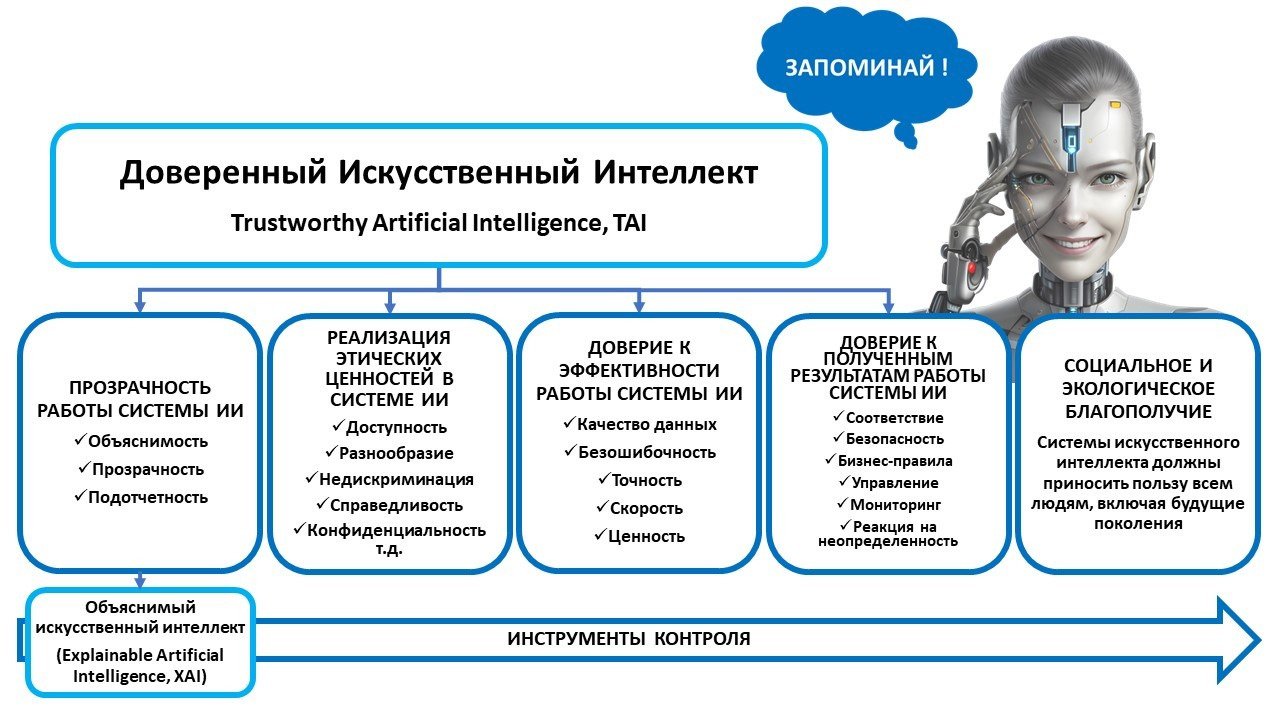
Что такое «доверенный искусственный интеллект»?
Системой доверенного искусственного интеллекта называют прикладную систему искусственного интеллекта, обеспечивающую выполнение возложенных на нее задач с учетом ряда дополнительных требований, учитывающих этические аспекты применения искусственного интеллекта, которая обеспечивает доверие к результатам ее работы, которые, в свою очередь, включают в себя: достоверность (надежность) и интерпретируемость выводов и предлагаемых решений, полученных с помощью системы и проверенных на верифицированных тестовых примерах; безопасность как с точки зрения невозможности причинения вреда пользователям системы на протяжении всего жизненного цикла системы, так и с точки зрения защиты от взлома, несанкционированного доступа и других негативных внешних воздействий, приватность и проверяемость данных, с которыми работают алгоритмы искусственного интеллекта, включая разграничение доступа и другие связанные с этим вопросы.
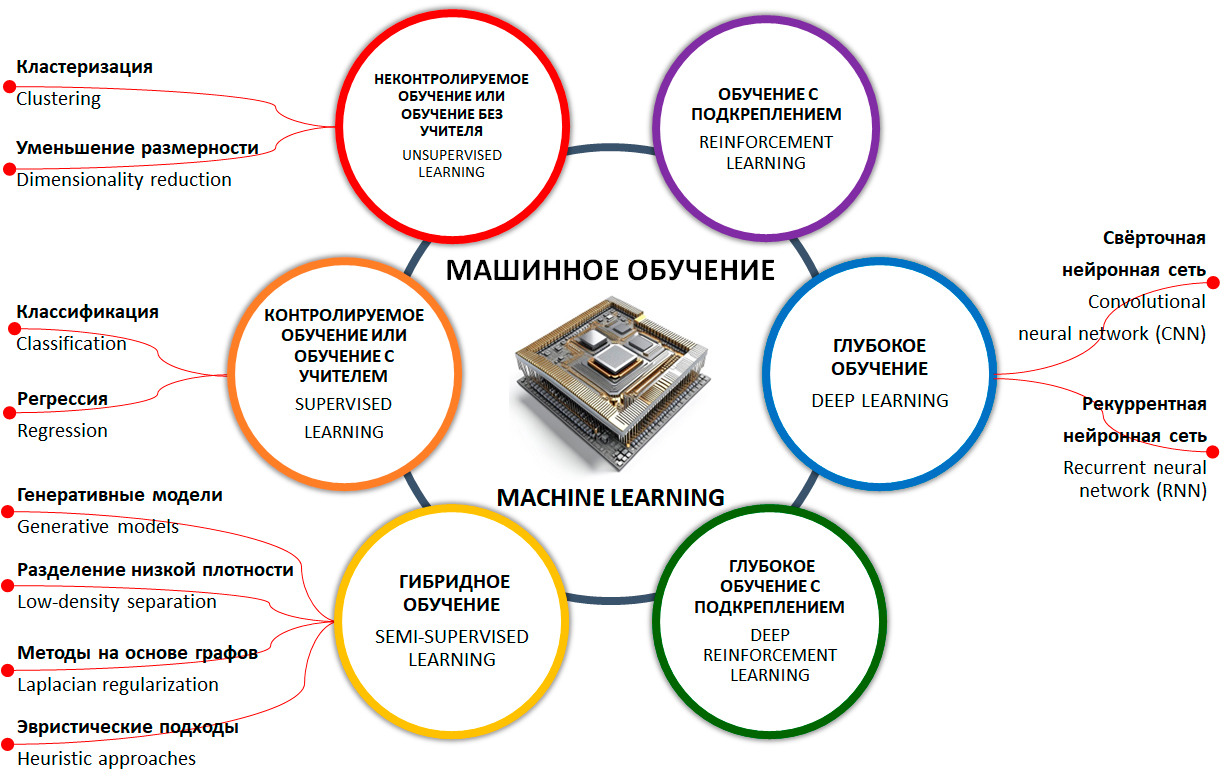
А что же тогда такое «машинное обучение»?
Машинное обучение — это одно из направлений (подмножеств) искусственного интеллекта, благодаря которому воплощается ключевое свойство интеллектуальных компьютерных систем — самообучение на основе анализа и обработки больших разнородных данных. Чем больше объем информации и ее разнообразие, тем проще искусственному интеллекту найти закономерности и тем точнее будет получаемый результат.
Чтобы заинтересовать уважаемого читателя, приведем еще несколько «забавных» примеров.
Слышали ли вы когда-нибудь о «Трансгуманистах»?
С одной стороны, как идея Трансгуманизм (Transhumanism) — это расширение возможностей человека с помощью науки. С другой стороны — это философская концепция и международное движение, приверженцы которого желают стать «постлюдьми» и преодолеть всевозможные физические ограничения, болезни, душевные страдания, старость и смерть благодаря использованию возможностей нано- и био- технологий, искусственного интеллекта и когнитивной науки.
На наш взгляд, идеи «трансгуманизма» очень тесно пересекаются с идеями и концепциями «цифрового человеческого бессмертия».

Несомненно, вы слышали и конечно знаете, кто такой «Data Scientist» — ученый и специалист по работе с данными.
А слышали ли вы когда-нибудь о «датасатанистах»? :-)
Датасатанисты — это определение, придуманное авторами, но отражающее современную действительность (наравне, например, с термином «инфоцыганщина»), которая сформировалась в период популяризации и повсеместной реализации идей искусственного интеллекта в современном информационном обществе. По своей сути датасатанисты — это мошенники и преступники, которые очень умело маскируются под ученых и специалистов в области ИИ и МО, но при этом пользуются чужими заслугами, знаниями и опытом, в своих корыстных целях и целях незаконного обогащения.
А, как вам такой термин — «библеоклазм»?
Библиоклазм — человек, в силу своего трансформированного мировоззрения и чрезмерно раздутого эго, из зависти или какой-либо другой корыстной цели, который стремится уничтожить книги других авторов. Вы не поверите, но таких людей, как «датасатанисты» или «библиоклазмы» сейчас достаточно.
А, как вам такие термины: «искусственная жизнь», «искусственный сверхинтеллект», «нейроморфный искусственный интеллект», «человеко-ориентированный искусственный интеллект», «синтетический интеллект», «распределенный искусственный интеллект», «дружественный искусственный интеллект», «дополненный искусственный интеллект», «композитный искусственный интеллект», «объяснимый искусственный интеллект», «причинно-следственный искусственный интеллект», «символический искусственный интеллект» и многие другие (все они есть в этой книге).
Таких примеров «удивительных» терминов мы можем привести еще не мало. Но в своей работе мы не стали тратить время на «суровую действительность» и сместили акцент на конструктивный и позитивный настрой. Одним словом, мы провели для Вас большую работу и собрали более 2500 терминов и определений по машинному обучению и искусственному интеллекту на основе своего опыта и данных из огромного числа различных источников.
2500 терминов и определений.
Много это или мало?
Наш опыт подсказывает, что для взаимопонимания двум собеседникам достаточно знать десяток или, максимум, два десятка определений. Но, когда дело касается профессиональной деятельности, то может получиться так, что мало знать, даже, несколько десятков терминов.
В этой книге приведены самые актуальные термины и определения, по-нашему мнению, наиболее часто употребляемые, как в повседневной работе, так и профессиональной деятельности специалистами самых разных профессий, интересующихся темой «искусственного интеллекта».
Мы очень старались сделать для вас нужный и полезный «инструмент» для вашей работы.
В заключение хочется добавить и проинформировать уважаемого читателя о том, что эта книга является абсолютно открытым и свободным к распространению документом. В случае, если Вы используете ее в своей практической работе, просим Вас делать ссылку на нее.
Многие из терминов и определений к ним, в этой книге, встречаются в сети Интернет. Они повторяются десятки или сотни раз на различных информационных ресурсах (в основном на зарубежных). Тем не менее, мы поставили перед собой цель — собрать и систематизировать самые актуальные из них в одном месте из самых разных источников, нужные из них перевести на русский язык и/или адаптировать, а какие-то и написать заново, исходя из собственного опыта.
Учитывая вышесказанное, мы не претендуем на авторство или уникальность представленных терминов и определений, но, несомненно, мы внесли свой собственный вклад в систематизацию и адаптацию многих из них.
Книга написана, прежде всего, для вашего удовольствия.
Мы продолжаем работу по улучшению качества и содержания текста этой книги, в том числе дополняем ее новыми знаниями по предметной области. Будем вам благодарны за любые отзывы, предложения и уточнения. Направляйте их, пожалуйста, на aleksander.chesalov@yandex.ru
Приятного Вам чтения и продуктивной работы!
Ваши, Александр Чесалов, Александр Власкин и Матвей Баканач.
16.08.2022. Издание первое.
09.03.2023. Издание второе. Исправленное и дополненное.
01.01.2024. Издание третье. Исправленное и дополненное.

Глоссариум по искусственному интеллекту
«А»
А/B-тестирование, также известное как сплит-тестирование (A/B Testing) — это процесс экспериментирования, при котором две или более версии переменной (веб-страницы, элемента страницы и т.д.) одновременно демонстрируются разным сегментам посетителей веб-сайта, чтобы определить, какая версия оказывает максимальное влияние и повышает бизнес-показатели.
Абдуктивное логическое программирование (Abductive logic programming, ALP) — это высокоуровневая структура представления знаний, которая может использоваться для решения проблем декларативно — на основе абдуктивного рассуждения. Она расширяет нормальное логическое программирование, позволяя некоторым предикатам быть неполно определенными, объявленными как абдуктивные предикаты.
Абдукция (Abductive reasoning) — (от латинского ab — «c, от», ducere — «водить») — это форма логического вывода, которая начинается с наблюдения или набора наблюдений, а затем пытается найти самое простое и наиболее вероятное объяснение. Этот процесс, в отличие от дедуктивного рассуждения, дает правдоподобный вывод, но не подтверждает его основаниями для вывода.
Абстрактный тип данных (Abstract data type) — это математическая модель для типов данных, где тип данных определяется поведением (семантикой) с точки зрения пользователя, а именно в терминах возможных значений, возможных операций над данными этого типа и поведения этих операций. Формально АТД может быть определён как множество объектов, определяемое списком компонентов (операций, применимых к этим объектам, и их свойств).
Абстракция (Abstraction) — это использование только тех характеристик объекта, которые с достаточной точностью представляют его в данной системе. Основная идея состоит в том, чтобы представить объект минимальным набором полей и методов и при этом с достаточной точностью для решаемой задачи.
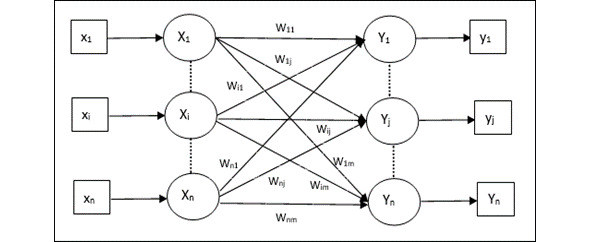
Автоассоциативная память (Auto Associative Memory) — это однослойная нейронная сеть, в которой входной обучающий вектор и выходные целевые векторы совпадают. Веса определяются таким образом, чтобы сеть хранила набор шаблонов. Как показано на следующем рисунке, архитектура сети автоассоциативной памяти имеет «n» количество входных обучающих векторов и аналогичное «n» количество выходных целевых векторов.
Автокодер (Автоэнкодер) (Autoencoder, AE) — это нейронная сеть, которая копирует входные данные на выход. По архитектуре похож на персептрон. Автоэнкодеры сжимают входные данные для представления их в latent-space (скрытое пространство), а затем восстанавливают из этого представления output (выходные данные). Цель — получить на выходном слое отклик, наиболее близкий к входному. Отличительная особенность автоэнкодеров — количество нейронов на входе и на выходе совпадает.
Автоматизация (Automation) — это технология, с помощью которой процесс или процедура выполняется с минимальным участием человека.
Автоматизированная обработка персональных данных (Automated processing of personal data) — это обработка персональных данных с помощью средств вычислительной техники.
Автоматизированная система (Automated system) — это организационно-техническая система, которая гарантирует выработку решений, основанных на автоматизации информационных процессов во всевозможных отраслях деятельности.
Автоматизированная система управления (Automated control system) — это комплекс программных и программно-аппаратных средств, предназначенных для контроля за технологическим и (или) производственным оборудованием (исполнительными устройствами) и производимыми ими процессами, а также для управления такими оборудованием и процессами.
Автоматизированное мышление (Automated reasoning) — это область информатики, которая занимается применением рассуждений в форме логики к вычислительным системам. Если задан набор предположений и цель, автоматизированная система рассуждений должна быть способна автоматически делать логические выводы для достижения этой цели.
Автономное транспортное средство (Autonomous vehicle) — это вид транспорта, основанный на автономной системе управления. Управление автономным транспортным средством полностью автоматизировано и осуществляется без водителя при помощи оптических датчиков, радиолокации и компьютерных алгоритмов.
Автономность (Autonomous) — это способность машины выполнять свою задачу без вмешательства и контроля человека.
Автономные вычисления (Autonomic computing) — это способность системы к адаптивному самоуправлению собственными ресурсами для высокоуровневых вычислительных функций без ввода данных пользователем.
Автономный автомобиль (Autonomous car) — это транспортное средство, способное воспринимать окружающую среду и работать без участия человека. Пассажир-человек не обязан брать на себя управление транспортным средством в любое время, и пассажиру-человеку вообще не требуется присутствовать в транспортном средстве. Автономный автомобиль может проехать везде, где ездит традиционный автомобиль, и делать все то же, что и опытный водитель-человек.
Автономный вывод (Offline inference) — это генерация группы прогнозов, сохранение этих прогнозов, а затем извлечение этих прогнозов по запросу.
Автономный искусственный интеллект (Autonomous artificial intelligence) — это биологически инспирированная система, которая пытается воспроизвести устройство мозга, принципы его действия со всеми вытекающими отсюда свойствами,.
Автономный робот (Autonomous robot) — это робот, который спроектирован и сконструирован так, чтобы самостоятельно взаимодействовать с окружающей средой и работать в течение длительных периодов времени без вмешательства человека. Автономные роботы часто обладают сложными функциями, которые могут помочь им воспринимать физическое окружение и автоматизировать действия и процессы, которые раньше выполнялись руками человека.
Авторегрессионная модель (Autoregressive Model) — это модель временного ряда, в которой наблюдения за предыдущими временными шагами используются в качестве входных данных для уравнения регрессии для прогнозирования значения на следующем временном шаге. В статистике и обработке сигналов авторегрессионная модель представляет собой тип случайного процесса. Он используется для описания некоторых изменяющихся во времени процессов в природе, экономике и т.д..
Агент (Agent) в обучении с подкреплением — это испытуемая система, которая обучается и взаимодействует с некоторой средой. Агент воздействует на среду, а среда воздействует на агента.
Агрегат (Aggregate) — это сумма, созданная из более мелких единиц. Например, население области — это совокупность населения городов, сельских районов и т.д., входящих в состав области. Суммировать данные из меньших единиц в большую единицу.
Агрегатор (Aggregator) — это тип программного обеспечения, которое объединяет различные типы веб-контента и предоставляет его в виде легкодоступного списка. Агрегаторы каналов собирают такие данные, как онлайн-статьи из газет или цифровых изданий, публикации в блогах, видео, подкасты и т. д. Агрегатор каналов также известен как агрегатор новостей, программа для чтения каналов, агрегатор контента или программа для чтения RSS.
Агломеративная кластеризация (Agglomerative clustering) — это один из алгоритмов кластеризации, в котором процесс группировки похожих экземпляров начинается с создания нескольких групп, где каждая группа содержит один объект на начальном этапе, затем он находит две наиболее похожие группы, объединяет их, повторяет процесс до тех пор, пока не получит единую группу наиболее похожих экземпляров.
Адаптивная система (Adaptive system) — это система, которая автоматически изменяет данные алгоритма своего функционирования и (иногда) свою структуру для поддержания или достижения оптимального состояния при изменении внешних условий.
Адаптивная система нейро-нечеткого вывода (Adaptive neuro fuzzy inference system) (ANFIS) (также адаптивная система нечеткого вывода на основе сети) — это разновидность искусственной нейронной сети, основанная на системе нечеткого вывода Такаги-Сугено. Методика была разработана в начале 1990-х годов. Поскольку она объединяет как нейронные сети, так и принципы нечеткой логики, то может использовать одновременно все имеющиеся преимущества в одной структуре. Его система вывода соответствует набору нечетких правил ЕСЛИ-ТО, которые имеют возможность обучения для аппроксимации нелинейных функций. Следовательно, ANFIS считается универсальной оценочной функцией. Для более эффективного и оптимального использования ANFIS можно использовать наилучшие параметры, полученные с помощью генетического алгоритма.
Адаптивный алгоритм (Adaptive algorithm) — это алгоритм, который пытается выдать лучшие результаты путём постоянной подстройки под входные данные. Такие алгоритмы применяются при сжатии без потерь. Классическим вариантом можно считать Алгоритм Хаффмана,.
Адаптивный градиентный алгоритм (Adaptive Gradient Algorithm) (AdaGrad) — это cложный алгоритм градиентного спуска, который перемасштабирует градиент отдельно на каждом параметре, эффективно присваивая каждому параметру независимый коэффициент обучения.
Аддитивные технологии (Additive technologies) — это технологии послойного создания трехмерных объектов на основе их цифровых моделей («двойников»), позволяющие изготавливать изделия сложных геометрических форм и профилей.
Айзек Азимов (Isaac Asimov) (1920—1992) — автор научной фантастики, сформулировал три закона робототехники, которые продолжают оказывать влияние на исследователей в области робототехники и искусственного интеллекта (ИИ).
Три закона робототехники Айзека Азимова (Three Laws of Robotics by Isaac Asimov) — Робот не может причинить вред человеку или своим бездействием допустить, чтобы человеку был причинен вред. Робот должен подчиняться приказам, отданным ему людьми, за исключением случаев, когда такие приказы противоречат Первому закону. Робот должен защищать свое существование до тех пор, пока такая защита не противоречит Первому или Второму закону.
Активное обучение/Стратегия активного обучения (Active Learning/ Active Learning Strategy) — это особый способ полууправляемого машинного обучения, в котором обучающий агент может в интерактивном режиме запрашивать оракула (обычно человека-аннотатора) для получения меток в новых точках данных. Подход к такому обучению основывается на самостоятельном выборе алгоритма некоторых данных из массы тех, на которых он учится. Активное обучение особенно ценно, когда помеченных примеров мало или их получение слишком затратно. Вместо слепого поиска разнообразных помеченных примеров алгоритм активного обучения выборочно ищет конкретный набор примеров, необходимых для обучения,,.
Алгоритм (Algorithm) — это точное предписание о выполнении в определенном порядке системы операций для решения любой задачи из некоторого данного класса (множества) задач. Термин «алгоритм» происходит от имени узбекского математика Мусы аль-Хорезми, который еще в 9 веке (ок. 820 г. н.э.) предложил простейшие арифметические алгоритмы. В математике и кибернетике класс задач определенного типа считается решенным, когда для ее решения установлен алгоритм. Нахождение алгоритмов является естественной целью человека при решении им разнообразных классов задач. Также, алгоритм — это набор правил или инструкций, данных ИИ, нейронной сети или другим машинам, чтобы помочь им учиться самостоятельно; классификация, кластеризация, рекомендация и регрессия — четыре самых популярных типа.
Алгоритм BLEU (BLEU) — это алгоритм оценки качества текста, который был автоматически переведен с одного естественного языка на другой. Качество считается соответствием между переводом машины и человека: «чем ближе машинный перевод к профессиональному человеческому переводу, тем лучше» — это основная идея BLEU.
Алгоритм Q-обучения (Q-learning) — это алгоритм обучения, основанный на ценностях. Алгоритмы на основе значений обновляют функцию значений на основе уравнения (в частности, уравнения Беллмана). В то время как другой тип, основанный на политике, оценивает функцию ценности с помощью жадной политики, полученной из последнего улучшения политики. Табличное Q-обучение (при обучении с подкреплением) представляет собой реализацию Q-обучения с использованием таблицы для хранения Q-функций для каждой комбинации состояния и действия. «Q» в Q-learning означает качество. Качество здесь показывает, насколько полезно данное действие для получения вознаграждения в будущем.
Алгоритм дерева соединений (также алгоритм Хьюгина) (Junction tree algorithm) — это метод, используемый в машинном обучении для извлечения маргинализации в общих графах. Граф называется деревом, потому что он разветвляется на разные разделы данных; узлы переменных являются ветвями,.
Алгоритм любого времени (Anytime algorithm) — это алгоритм, который может дать частичный ответ, качество которого зависит от объема вычислений, которые он смог выполнить. Ответ, генерируемый алгоритмами anytime, является приближенным к правильному. Большинство алгоритмов выполняются до конца: они дают единственный ответ после выполнения некоторого фиксированного объема вычислений. Однако в некоторых случаях пользователь может захотеть завершить алгоритм до его завершения. Эта особенность алгоритмов anytime моделируется такой теоретической конструкцией, как предельная машина Тьюринга (Бургин, 1992; 2005).
Алгоритм обучения (Learning Algorithm) — это фрагменты кода, которые помогают исследовать, анализировать и находить смысл в сложных наборах данных. Каждый алгоритм представляет собой конечный набор однозначных пошаговых инструкций, которым машина может следовать для достижения определенной цели. В модели машинного обучения цель состоит в том, чтобы установить или обнаружить шаблоны, которые люди могут использовать для прогнозирования или классификации информации. Они используют параметры, основанные на обучающих данных — подмножестве данных, которое представляет больший набор. По мере расширения обучающих данных для более реалистичного представления мира, алгоритм вычисляет более точные результаты.
Алгоритм оптимизации Адам (Adam optimization algorithm) — это расширение стохастического градиентного спуска, который в последнее время получил широкое распространение для приложений глубокого обучения в области компьютерного зрения и обработки естественного языка.
Алгоритм оптимизации роя светлячков (Glowworm swarm optimization algorithm) — это метаэвристический алгоритм без производных, имитирующий поведение свечения светлячков, который может эффективно фиксировать все максимальные мультимодальные функции.
Алгоритм Персептрона (Perceptron algorithm) — это линейный алгоритм машинного обучения для задач бинарной классификации. Его можно считать одним из первых и одним из самых простых типов искусственных нейронных сетей. Это определенно не «глубокое» обучение, но это важный строительный блок. Как и логистическая регрессия, он может быстро изучить линейное разделение в пространстве признаков для задач классификации двух классов, хотя, в отличие от логистической регрессии, он обучается с использованием алгоритма оптимизации стохастического градиентного спуска и не предсказывает калиброванные вероятности.
Алгоритм поиска (Search algorithm) — это любой алгоритм, который решает задачу поиска, а именно извлекает информацию, хранящуюся в некоторой структуре данных или вычисленную в пространстве поиска проблемной области, либо с дискретными, либо с непрерывными значениями.
Алгоритм пчелиной колонии (алгоритм оптимизации подражанием пчелиной колонии, artificial bee colony optimization, ABC) (Bees algorithm) — это один из полиномиальных эвристических алгоритмов для решения оптимизационных задач в области информатики и исследования операций. Относится к категории стохастических биоинспирированных алгоритмов, базируется на имитации поведения колонии медоносных пчел при сборе нектара в природе.
Алгоритмическая оценка (Algorithmic Assessment) — это техническая оценка, которая помогает выявлять и устранять потенциальные риски и непредвиденные последствия использования систем искусственного интеллекта, чтобы вызвать доверие и создать поддерживающие системы вокруг принятия решений ИИ.
Алгоритмическая предвзятость (Biased algorithm) — это систематические и повторяющиеся ошибки в компьютерной системе, которые приводят к несправедливым результатам, например, привилегия одной произвольной группы пользователей над другими,.
Алгоритмы машинного обучения (Machine learning algorithms) — это фрагменты кода, которые помогают пользователям исследовать и анализировать сложные наборы данных и находить в них смысл или закономерность. Каждый алгоритм — это конечный набор однозначных пошаговых инструкций, которые компьютер может выполнять для достижения определенной цели. В модели машинного обучения цель заключается в том, чтобы установить или обнаружить закономерности, с помощью которых пользователи могут создавать прогнозы либо классифицировать информацию. В алгоритмах машинного обучения используются параметры, основанные на учебных данных (подмножество данных, представляющее более широкий набор). При расширении учебных данных для более реалистичного представления мира с помощью алгоритма вычисляются более точные результаты. В различных алгоритмах применяются разные способы анализа данных. Они часто группируются по методам машинного обучения, в рамках которых используются: контролируемое обучение, неконтролируемое обучение и обучение с подкреплением. В наиболее популярных алгоритмах для прогнозирования целевых категорий, поиска необычных точек данных, прогнозирования значений и обнаружения сходства используются регрессия и классификация.
Анализ алгоритмов (Analysis of algorithms) — это область на границе компьютерных наук и математики. Цель его состоит в том, чтобы получить точное представление об асимптотических характеристиках алгоритмов и структур данных в усредненном виде. Объединяющей темой является использование вероятностных, комбинаторных и аналитических методов. Объектами изучения являются случайные ветвящиеся процессы, графы, перестановки, деревья и строки.
Анализ временных рядов (Time series analysis) — это раздел машинного обучения и статистики, который анализирует временные данные. Многие типы задач машинного обучения требуют анализа временных рядов, включая классификацию, кластеризацию, прогнозирование и обнаружение аномалий. Например, вы можете использовать анализ временных рядов, чтобы спрогнозировать будущие продажи зимних пальто по месяцам на основе исторических данных о продажах,.
Анализ данных (Data analysis) — это область математики и информатики, занимающаяся построением и исследованием наиболее общих математических методов и вычислительных алгоритмов извлечения знаний из экспериментальных (в широком смысле) данных; процесс исследования, фильтрации, преобразования и моделирования данных с целью извлечения полезной информации и принятия решений. Анализ данных имеет множество аспектов и подходов, охватывает разные методы в различных областях науки и деятельности.
Анализ настроений (Sentiment analysis) — это использование статистических алгоритмов или алгоритмов машинного обучения для определения общего отношения группы — положительного или отрицательного — к услуге, продукту, организации или теме. Например, используя понимание естественного языка, алгоритм может выполнять анализ настроений по текстовой обратной связи по университетскому курсу, чтобы определить степень, в которой студентам в целом понравился или не понравился учебный курс.
Анализ основных компонентов (PCA) (Principal component analysis (PCA)) — это построение новых функций, которые являются основными компонентами набора данных. Главные компоненты представляют собой случайные величины максимальной дисперсии, построенные из линейных комбинаций входных признаков. Эквивалентно, они являются проекциями на оси главных компонентов, которые представляют собой линии, минимизирующие среднеквадратичное расстояние до каждой точки в наборе данных. Чтобы обеспечить уникальность, все оси главных компонентов должны быть ортогональны. PCA — это метод максимального правдоподобия для линейной регрессии при наличии гауссовского шума как на входе, так и на выходе. В некоторых случаях PCA соответствует преобразованию Фурье, например DCT, используемому при сжатии изображений JPEG.
Аналитика принятия решений (Decision intelligence) — это практическая дисциплина, используемая для улучшения процесса принятия решений путем четкого понимания и программной разработки того, как принимаются решения, и как итоговые результаты оцениваются, управляются и улучшаются с помощью обратной связи.
Аналитика данных (Data analytics) — это наука об анализе необработанных данных, чтобы делать выводы об этой информации. Многие методы и процессы анализа данных были автоматизированы в механические процессы и алгоритмы, которые работают с необработанными данными для потребления человеком.
Аннотация (Annotation) — это специальный модификатор, используемый в объявлении класса, метода, параметра, переменной, конструктора и пакета, а также инструмент, выбранный стандартом JSR-175 для описания метаданных.
Аннотация объекта (Entity annotation) — это процесс маркировки неструктурированных предложений такой информацией, чтобы машина могла их прочитать. Это может включать, например, маркировку всех людей, организаций и местоположений в документе.
Анонимизация (Anonymization) — это процесс удаления данных (из документов, баз данных и т.д.) с целью сокрытия источника информации, действующего лица и т. д. Например: анонимизация выписки из стационара процесс удаления данных с целью предотвращения идентификации личности пациента.
Ансамбль (Ensemble) — это слияние прогнозов нескольких моделей. Можно создать ансамбль с помощью одного или нескольких из следующих способов: различные инициализации; различные гиперпараметры; другая общая структура. Глубокие и широкие модели представляют собой своеобразный ансамбль.
Антивирусное программное обеспечение (Antivirus software) — это программа или набор программ, предназначенных для предотвращения, поиска, обнаружения и удаления программных вирусов и других вредоносных программ, таких как черви, трояны, рекламное ПО и т.д..
АПИ-как-услуга (API-AS-a-service) — это подход, который сочетает в себе экономию API и аренду программного обеспечения и предоставляет интерфейсы прикладного программирования как услугу.
АПИ набора данных (Dataset API) — это высокоуровневый API TensorFlow для чтения данных и преобразования их в форму, требуемую алгоритмом машинного обучения. Объект tf. data. Dataset представляет собой последовательность элементов, в которой каждый элемент содержит один или несколько тензоров. Объект tf.data.Iterator обеспечивает доступ к элементам набора данных.
Аппаратное обеспечение (Hardware) — это система взаимосвязанных технических устройств, предназначенных для ввода (вывода), обработки и хранения данных.
Аппаратное обеспечение ИИ (AI hardware, AI-enabled hardware, AI hardware platform) — это аппаратное обеспечение ИИ, аппаратные средства ИИ, аппаратная часть инфраструктуры или системы искусственного интеллекта, ИИ-инфраструктуры.
Аппаратное ускорение (Hardware acceleration) — это применение аппаратного обеспечения для выполнения некоторых функций быстрее по сравнению с выполнением программ процессором общего назначения.
Аппаратно-программный комплекс (Hardware-software complex) — это набор технических и программных средств, работающих совместно для выполнения одной или нескольких сходных задач.
Аппаратный акселератор (Hardware accelerator) — это устройство, выполняющее некоторый ограниченный набор функций для повышения производительности всей системы или отдельной её подсистемы. Например, purpose-built hardware accelerator — специализированный аппаратный ускоритель.
Аппаратный Сервер (аппаратное обеспечение) (Hardware Server) — это выделенный или специализированный компьютер для выполнения сервисного программного обеспечения (в том числе серверов тех или иных задач) без непосредственного участия человека. Одновременное использование как высокопроизводительных процессоров, так и FPGA позволяет обрабатывать сложные гибридные приложения.
Априорное (Prior) — это распределение вероятностей, которое будет представлять ранее существовавшие убеждения о конкретной величине до того, как будут рассмотрены новые данные.
Артефакт (Artifact) — это один из многих видов материальных побочных продуктов, производимых в процессе разработки программного обеспечения. Некоторые артефакты (например, варианты использования, диаграммы классов и другие модели унифицированного языка моделирования (UML), требования и проектные документы) помогают описать функции, архитектуру и дизайн программного обеспечения. Другие артефакты связаны с самим процессом разработки, например, планы проектов, бизнес-кейсы и оценки рисков.
Архивное хранилище (Archival Storage) — это источник данных, которые не нужны для повседневных операций организации, но к которым может потребоваться доступ время от времени. Используя архивное хранилище, организации могут использовать вторичные источники, сохраняя при этом защиту данных. Использование источников архивного хранения снижает необходимые затраты на первичное хранение и позволяет организации поддерживать данные, которые могут потребоваться для соблюдения нормативных или других требований.
Архивный пакет информации (AIC) (Archival Information Collection (AIC)) — это информация, содержание которой представляет собой агрегацию других пакетов архивной информации. Функция цифрового сохранения сохраняет способность регенерировать провалы (пакеты информации) по мере необходимости с течением времени.
Архитектура агента (Agent architecture) — это план программных агентов и интеллектуальных систем управления, изображающий расположение компонентов. Архитектуры, реализованные интеллектуальными агентами, называются когнитивными архитектурами.
Архитектура вычислительной машины (Architecture of a computer) — это концептуальная структура вычислительной машины, определяющая проведение обработки информации и включающая методы преобразования информации в данные и принципы взаимодействия технических средств и программного обеспечения.
Архитектура вычислительной системы (Architecture of a computing system) — это конфигурация, состав и принципы взаимодействия (включая обмен данными) элементов вычислительной системы.
Архитектура механизма обработки матриц (MPE) (Matrix Processing Engine Architecture) — это многомерный массив обработки физических матриц цифровых устройств с умножением (MAC), который вычисляет серию матричных операций сверточной нейронной сети,.
Архитектура системы (Architecture of a system) — это принципиальная организация системы, воплощенная в её элементах, их взаимоотношениях друг с другом и со средой, а также принципы, направляющие её проектирование и эволюцию.
Архитектура фон Неймана (Von Neumann architecture) — это широко известный принцип совместного хранения команд и данных в памяти компьютера. Вычислительные машины такого рода часто обозначают термином «машина фон Неймана», однако соответствие этих понятий не всегда однозначно. В общем случае, когда говорят об архитектуре фон Неймана, подразумевают принцип хранения данных и инструкций в одной памяти.
Архитектурная группа описаний (Architectural description group, Architectural view) — это представление системы в целом с точки зрения связанного набора интересов,.
Архитектурный фреймворк (Architectural frameworks) — это высокоуровневые описания организации как системы; они охватывают структуру его основных компонентов на разных уровнях, взаимосвязи между этими компонентами и принципы, определяющие их эволюцию.
Асимптотическая вычислительная сложность (Asymptotic computational complexity) — это использование асимптотического анализа для оценки вычислительной сложности алгоритмов и вычислительных задач, обычно связанных с использованием большой нотации O. Асимптотическая сложность является ключом к сравнению алгоритмов. Асимптотическая сложность раскрывает более глубокие математические истины об алгоритмах, которые не зависят от аппаратного обеспечения.
Асинхронные межкристальные протоколы (Asynchronous inter-chip protocols) — это протоколы для обмена данных в низкоскоростных устройствах; для управления обменом данными используются не кадры, а отдельные символы.
Ассоциация (Association) — это еще один тип метода обучения без учителя, который использует разные правила для поиска взаимосвязей между переменными в заданном наборе данных. Эти методы часто используются для анализа потребительской корзины и механизмов рекомендаций, подобно рекомендациям «Клиенты, которые купили этот товар, также купили».
Ассоциация по развитию искусственного интеллекта (Association for the Advancement of Artificial Intelligence) — это международное научное сообщество, занимающееся продвижением исследований и ответственным использованием искусственного интеллекта. AAAI также стремится повысить общественное понимание искусственного интеллекта (ИИ), улучшить обучение и подготовку специалистов, занимающихся ИИ, и предоставить рекомендации для планировщиков исследований и спонсоров относительно важности и потенциала текущих разработок ИИ и будущих направлений.
Атрибутивное исчисление (Attributional calculus) — это типизированная логическая система, сочетающая элементы логики высказываний, исчисления предикатов и многозначной логики с целью естественной индукции. Под естественной индукцией понимается форма индуктивного обучения, которая генерирует гипотезы в формах, ориентированных на человека, то есть в формах, которые кажутся людям естественными, их легко понять и соотнести с человеческим знанием. Для достижения этой цели AИ включает нетрадиционные логические операции и формы, которые могут сделать логические выражения более простыми и более тесно связанными с эквивалентными описаниями на естественном языке.
Аффективные вычисления (также искусственный эмоциональный интеллект или эмоциональный ИИ) (Affective computing) — это вычисления, в которых системы и устройства могут распознавать, интерпретировать, обрабатывать и имитировать человеческие аффекты. Это междисциплинарная область, охватывающая информатику, психологию и когнитивную науку.
«Б»
База данных (Database) — это упорядоченный набор структурированной информации или данных, которые обычно хранятся в электронном виде в компьютерной системе. База данных обычно управляется системой управления базами данных (СУБД). Данные вместе с СУБД, а также приложения, которые с ними связаны, называются системой баз данных, или, для краткости, просто базой данных.
База Данных ImageNet (ImageNet) — это большая визуальная база данных, предназначенная для использования в исследованиях программного обеспечения для распознавания визуальных объектов. Более 14 миллионов изображений были вручную аннотированы в рамках проекта, чтобы указать, какие объекты изображены, и, по крайней мере, в одном миллионе изображений также предусмотрены ограничивающие рамки. ImageNet содержит более 20 000 категорий, среди которых типичная категория, такая как «воздушный шар» или «клубника», состоит из нескольких сотен изображений. База данных аннотаций URL-адресов сторонних изображений находится в свободном доступе непосредственно из ImageNet, хотя фактические изображения не принадлежат ImageNet. С 2010 года в рамках проекта ImageNet проводится ежегодный конкурс программного обеспечения ImageNet Large Scale Visual Recognition Challenge (ILSVRC), в котором программы соревнуются за правильную классификацию и обнаружение объектов и сцен. В задаче используется «усеченный» список из тысячи неперекрывающихся классов.
База данных MNIST (MNIST) — это база данных образцов рукописного написания цифр от 0 до 9, содержит 60 000 образцов наборов данных для обучения и тестовый набор из 10 000 образцов. Цифры были нормализованы по размеру и расположены в центре изображения фиксированного размера. Каждое изображение хранится в виде массива целых чисел 28x28, где каждое целое число представляет собой значение в оттенках серого от 0 до 255 включительно. MNIST — это канонический набор данных для машинного обучения, часто используемый для тестирования новых подходов к машинному обучению. Это часть большой базы данных рукописных форм и символов, опубликованной Национальным институтом стандартов и технологий США (NIST).
Базовый уровень (Baseline) — это модель, используемая в качестве контрольной точки для сравнения того, насколько хорошо работает другая модель (как правило, более сложная). Например, модель логистической регрессии может служить базовым уровнем для глубокой модели. Для конкретной проблемы базовый уровень помогает разработчикам моделей количественно определить минимальную ожидаемую производительность, которую новая модель должна обеспечить, чтобы быть полезной.
Байесовская оптимизация (Bayesian optimization) — это метод вероятностной регрессионной модели для оптимизации ресурсоемких целевых функций путем оптимизации суррогата с помощью байесовского метода обучения. Поскольку байесовская оптимизация сама по себе очень дорогая, ее обычно используют для оптимизации дорогостоящих задач с небольшим количеством параметров, таких как выбор гиперпараметров.
Байесовская сеть (или Байесова сеть, Байесовская сеть доверия) (Bayesian Network) — это графическая вероятностная модель, представляющая собой множество переменных и их вероятностных зависимостей. Например, байесовская сеть может быть использована для вычисления вероятности того, чем болен пациент по наличию или отсутствию ряда симптомов, основываясь на данных о зависимости между симптомами и болезнями.
Байесовский классификатор в машинном обучении (Bayesian classifier in machine learning) — это семейство простых вероятностных классификаторов, основанных на использовании теоремы Байеса и «наивном» предположении о независимости признаков классифицируемых объектов. Анализ на основе байесовской классификации активно изучался и использовался начиная с 1950-х годов в области классификации документов, где в качестве признаков использовались частоты слов. Алгоритм является масштабируемым по числу признаков, а по точности сопоставим с другими популярными методами, такими как машины опорных векторов. Как и любой классификатор, байесовский присваивает метки классов наблюдениям, представленным векторами признаков. При этом предполагается, что каждый признак независимо влияет на вероятность принадлежности наблюдения к классу. Например, объект можно считать яблоком, если он имеет округлую форму, красный цвет и диаметр около 10 см. Наивный байесовский классификатор «считает», что каждый из этих признаков независимо влияет на вероятность того, что этот объект является яблоком, независимо от любых возможных корреляций между характеристиками цвета, формы и размера. Простой байесовский классификатор строится на основе обучения с учителем. Несмотря на мало реалистичное предположение о независимости признаков, простые байесовские классификаторы хорошо зарекомендовали себя при решении многих практических задач. Дополнительным преимуществом метода является небольшое число примеров, необходимых для обучения.
Байесовское программирование (Bayesian programming) — это формальная система и методология определения вероятностных моделей и решения задач, когда не вся необходимая информация является доступной,.
Башня (Tower) — это компонент глубокой нейронной сети, которая сама по себе является глубокой нейронной сетью без выходного слоя. Как правило, каждая башня считывает данные из независимого источника. Башни независимы до тех пор, пока их выходные данные не будут объединены в последнем слое.
Байт (Byte) — это восемь битов. Байт — это просто кусок из 8 единиц и нулей. Например: 01000001 — это байт. Компьютер часто работает с группами битов, а не с отдельными битами, и наименьшая группа битов, с которой обычно работает компьютер, — это байт. Байт равен одному столбцу в файле, записанном в символьном формате.
Безопасность критической информационной инфраструктуры (Security of a critical information infrastructure) — это состояние защищенности критической информационной инфраструктуры, обеспечивающее ее устойчивое функционирование при проведении в отношении ее компьютерных атак.
Безопасность приложений (Application security) — это процесс повышения безопасности приложений путем поиска, исправления и повышения безопасности приложений. Многое из этого происходит на этапе разработки, но включает инструменты и методы для защиты приложений после их развертывания. Это становится все более важным, поскольку хакеры все чаще атакуют приложения.
Бенчмарк (Benchmark) (также benchmark program, benchmarking program, benchmark test) — это тестовая программа или пакет для оценки (измерения и/или сравнения) различных аспектов производительности процессора, отдельных устройств, компьютера, системы или конкретного приложения, программного обеспечения; эталон, который позволяет сравнивать продукты разных производителей друг с другом или с некоторым стандартом. Например, онлайн-бенчмарк — онлайн-бенчмарк; стандартный бенчмарк — стандартный бенчмарк; сравнение времени бенчмарка — сравнение времени выполнения бенчмарка.
Бенчмаркинг (Benchmarking) — это набор методик, которые позволяют изучить опыт конкурентов и внедрить лучшие практики в своей компании.
Беспроводная сеть (Wireless network) — это компьютерная сеть, в которой используются беспроводные соединения для передачи данных между сетевыми узлами. Беспроводная сеть — это метод, с помощью которого дома, телекоммуникационные сети и бизнес-установки избегают дорогостоящего процесса ввода кабелей в здание или в качестве соединения между различными местоположениями оборудования. Административные телекоммуникационные сети обычно реализуются и администрируются с использованием радиосвязи. Эта реализация происходит на физическом уровне (слое) сетевой структуры модели OSI.
Беспроводная широкополосная связь (WiBB Wireless broadband) — это телекоммуникационная технология, которая обеспечивает высокоскоростной беспроводной доступ в Интернет или доступ к компьютерным сетям на большой территории. Этот термин включает как фиксированную, так и мобильную широкополосную связь.
БЕТА версия (BETA) — это термин, который относится к этапу разработки онлайн-сервиса, на котором сервис объединяется с точки зрения функциональности, но требуется подлинный пользовательский опыт, прежде чем сервис можно будет завершить ориентированным на пользователя способом. При разработке онлайн-сервиса цель бета-фазы состоит в том, чтобы распознать как проблемы программирования, так и процедуры, повышающие удобство использования. Бета-фаза особенно часто используется в связи с онлайн-сервисами и, может быть, либо бесплатной (открытая бета-версия), либо ограниченной для определенной целевой группы (закрытая бета-версия).
Библиотека Keras (The Keras Library) — это библиотека Python, используемая для глубокого обучения и создания искусственных нейронных сетей. Выпущенный в 2015 году, Keras предназначен для быстрого экспериментирования с глубокими нейронными сетями. Keras предлагает несколько инструментов, которые упрощают работу с изображениями и текстовыми данными. Помимо стандартных нейронных сетей, Keras также поддерживает сверточные и рекуррентные нейронные сети. В качестве бэкэнда Keras обычно использует TensorFlow, Microsoft Cognitive toolkit или Theano. Он удобен для пользователя и требует минимального кода для выполнения функций и команд. Keras имеет модульную структуру и имеет несколько методов предварительной обработки данных. Keras также предлагает методы. evaluate () и predict_classes () для тестирования и оценки моделей. Github и Slack организуют форумы сообщества для Keras.
Библиотека Matplotlib (Matplotlib) — это комплексная, популярная библиотека Python с открытым исходным кодом для создания визуализаций «качества публикации». Визуализации могут быть статическими, анимированными или интерактивными. Он был эмулирован из MATLAB и, таким образом, содержит глобальные стили, очень похожие на MATLAB, включая иерархию объектов.
Библиотека Numpy (Numpy) — это библиотека Python, представленная в 2006 году для поддержки многомерных массивов и матриц. Библиотека также позволяет программистам выполнять высокоуровневые математические вычисления с массивами и матрицами. Можно сказать, что это объединение своих предшественников — The Numeric и Numarray. NumPy является неотъемлемой частью Python и по существу предоставляет программе математические функции типа MATLAB. По сравнению с обычными списками Python, он занимает меньше памяти, удобен в использовании и имеет более быструю обработку. При интеграции с другими библиотеками, такими как SciPy и / или Matplotlib, его можно эффективно использовать для целей анализа данных и анализа данных.
Библиотека PyTorch & Torch (PyTorch (Torch Library) — это библиотека машинного обучения, которая в основном используется для приложений обработки естественного языка и компьютерного зрения. Разработанная исследовательской лабораторией искусственного интеллекта и выпущенная в сентябре 2016 года, это библиотека с открытым исходным кодом, основанная на библиотеке Torch для научных вычислений и машинного обучения. PyTorch предоставляет операции с объектом n-мерного массива, аналогичные NumPy, однако, кроме того, он предлагает более быстрые вычисления за счет интеграции с графическим процессором. PyTorch автоматически различает построение и обучение нейронных сетей. PyTorch — это внесла свой вклад в разработку нескольких программ глубокого обучения — Tesla Autopilot, Uber’s Pyro, PyTorch Lighten и т.д..
Библиотека Scikit-learn (Scikit-learn Library) — это простая в освоении библиотека Python с открытым исходным кодом для машинного обучения, построенная на NumPy, SciPy и matplotlib. Его можно использовать для классификации данных, регрессии, кластеризации, уменьшения размерности, выбора модели и предварительной обработки.
Библиотека SciPy (SciPy Library) — это библиотека Python с открытым исходным кодом для выполнения научных и технических вычислений на Python. Она была разработана открытым сообществом разработчиков, которое также поддерживает его поддержку и спонсирует разработки. SciPy предлагает несколько пакетов алгоритмов и функций, которые поддерживают научные вычисления: константы, кластер, fft, fftpack, интегрировать и т. д. SciPy по сути является частью стека NumPy и использует многомерные массивы в качестве структур данных, предоставляемых модулем NumPy. Первоначально выпущенный в 2001 году, она распространялась по лицензии BSD с репозиторием на GitHub.
Библиотека Seaborn (Seaborn) — это библиотека визуализации данных Python для построения «привлекательных и информативных» статистических графиков. Seaborn основан на Matplotlib. Он включает в себя множество визуализаций на выбор, включая временные ряды и совместные графики.
Библиотека Theano (Theano) — это библиотека Python, используемая для компиляции, определения, оптимизации и оценки математических выражений, содержащих многомерные массивы. Она была разработана Монреальским институтом алгоритмов обучения (MILA) при Монреальском университете и выпущена в 2007 году. Это библиотека с открытым исходным кодом под лицензией BSD. Библиотека построена поверх NumPy и имеет аналогичный интерфейс. Наряду с процессором он позволяет использовать графический процессор для ускорения вычислений. Theano вносит значительный вклад в крупномасштабные научные вычисления и связанные с ними исследования и поддерживается специальной группой из 13 разработчиков.
Биграмм (Bigram) — N-грамм, в которой N=2.
Бинарное дерево (Binary tree) — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. Как правило, первый называется родительским узлом, а дети называются левым и правым наследниками. Двоичное дерево не является упорядоченным ориентированным деревом.
Биннинг (машинное зрение) (Binning) — это процесс объединения заряда от соседних пикселей в CCD матрице во время считывания. Этот процесс выполняется до оцифровки в микросхеме ПЗС (Прибор с обратной Зарядной Связью — CCD матрица) с помощью специализированного управления последовательным и параллельным регистрами. Двумя основными преимуществами биннинга являются улучшенное отношение сигнал/ шум (SNR) и возможность увеличивать частоту кадров, хотя и за счет уменьшения пиксельного разрешения.
Биоконсерватизм (Bioconservatism) — это позиция нерешительности и скептицизма в отношении радикальных технологических достижений, особенно тех, которые направлены на изменение или улучшение условий жизни человека. Биоконсерватизм характеризуется верой в то, что технологические тенденции в современном обществе рискуют поставить под угрозу человеческое достоинство, а также противодействием движениям и технологиям, включая трансгуманизм, генетическую модификацию человека, «сильный» искусственный интеллект и технологическую сингулярность. Многие биоконсерваторы также выступают против использования таких технологий, как продление жизни и преимплантационный генетический скрининг,.
Биометрия (Biometrics) — это система распознавания людей по одному или более физическим или поведенческим чертам,.
Блок IFU (Instruction Fetch Unit, IFU) — это блок предвыборки команд, который выстраивает в единую очередь команды, считываемые из внутренней или внешней памяти системы по шине EIB в соответствии с адресом, выставляемым по шине IAB.
Блок обработки изображений (Vision Processing Unit, VPU) — это новый класс специализированных микропроцессоров, являющихся разновидностью ИИ -ускорителей, предназначенных для аппаратного ускорения работы алгоритмов машинного зрения.
Блокчейн (Blockchain) — это алгоритмы и протоколы децентрализованного хранения и обработки транзакций, структурированных в виде последовательности связанных блоков без возможности их последующего изменения.
Большая языковая модель (Large language model) — это неофициальный термин, который обычно означает языковую модель с большим количеством параметров. Некоторые большие языковые модели содержат более 100 миллиардов параметров.
Большие данные (Big data) — это термин для наборов цифровых данных. Большой размер данных и их сложность требует значительных вычислительных мощностей компьютеров и специальных программных инструментов для их анализа и представления. К большим данным относят массивы числовых данных, изображения, аудио и видео файлы.
Бритва Оккама (Occam’s razor) — это принцип принятия решения, сформулированный в XIV веке и франциским монахом Уильямом Оккаму, который. можно сформулировать так: «из двух конкурирующих теорий предпочтение следует отдавать более простому объяснению объекта». Этот принцип также выражается как «Сущности не должны умножаться сверх необходимости». Применительно к машинному обучению, в частности к теории обучения, интуитивную идею Бритвы Оккамы можно сформулировать так — Самое простое решение чаще всего является правильным!.
Булевая нейронная сеть (невесомая нейронная сеть) (Boolean neural network) — это многослойная нейронная сеть, состоящая из модуля самоорганизующейся нейронной сети для извлечения признаков, за которым следует модуль нейронной сети и модуль классификации нейронной сети, который прошел самостоятельную подготовку.
Бустинг (Boosting) — это мета-алгоритм ансамбля машинного обучения, предназначенный в первую очередь для уменьшения предвзятости и дисперсии в обучении с учителем, а также семейство алгоритмов машинного обучения, которые превращают слабых учеников в сильных.
Буфер воспроизведения (Replay buffer) — это память, используемая для хранения данных в промежутке между использованием или воспроизведением.
Быстрое кодирование (One-hot encoding) — это процесс, с помощью которого категориальные переменные преобразуются в подходящую алгоритмам Машинного обучения (ML) форму. Большая часть предварительной обработки данных — это кодирование в понятный компьютеру язык чисел. Отсюда и название «encode», что буквально означает «преобразовать в компьютерный код». Существует множество различных способов кодирования, таких как Ярлычное (Label Encoding) или Быстрое кодирование.
Быстрые и экономичные деревья (Fast-and-frugal trees) — это тип дерева классификации. FFTS можно использовать в качестве инструментов принятия решений, которые действуют как лексикографические классификаторы и, при необходимости, связывают действие (решение) с каждым классом или категорией.
Бытовой искусственный интеллект (Consumer artificial intelligence) — это специализированные программы искусственного интеллекта, внедрённые в бытовые устройства и процессы.
«В»
Валидационные данные (Holdout data) или «выделенные, удержанные» данные, являющиеся частью Датасета (Dataset), предназначенного для тестирования, проверки работоспособности машинного обучения. Тестовые данные относятся к части предварительно размеченных данных, которые хранятся вне наборов данных, используемых для обучения и проверки контролируемых моделей машинного обучения. Их также можно назвать эталонными данными. Первым шагом в обучении с учителем является тестирование различных моделей на тестовых данных и оценка моделей на предмет прогнозируемой производительности. После того, как модель проверена и настроена с помощью набора проверочных данных, она тестируется с набором данных, чтобы выполнить окончательную оценку ее точности, чувствительности, специфичности и согласованности при прогнозировании правильных результатов,.
Вариативность данных (Data variability) этот термин описывает, насколько далеко точки данных расположены друг от друга и от центра распределения. Наряду с мерами центральной тенденции меры изменчивости дают вам описательную статистику, которая обобщает ваши данные.
Ввод данных (Data entry) — это процесс преобразования устных или письменных ответов в электронную форму.
Вес (Weight) в обзорных исследованиях — это число, связанное со случаем или единицей анализа; вес используется как мера относительного вклада переменных этого случая при оценке всей совокупности. При использовании вероятностной выборки часто существует вероятность того, что некоторые элементы генеральной совокупности будут недостаточно или чрезмерно представлены в выборке. Чтобы обеспечить более точные оценки всей совокупности, каждому случаю присваиваются «веса», которые используются для корректировки общих результатов, чтобы они более точно соответствовали общей совокупности.
Векторный процессор или массивный процессор (Vector processor or array processor) — это центральный процессор (ЦП), который реализует набор инструкций, где его инструкции предназначены для эффективной и действенной работы с большими одномерными массивами данных, называемыми векторами. Это отличается от скалярных процессоров, чьи инструкции работают только с отдельными элементами данных, и от некоторых из тех же скалярных процессоров, имеющих дополнительные арифметические блоки с одной инструкцией, несколькими данными (SIMD) или SWAR. Векторные процессоры могут значительно повысить производительность при определенных рабочих нагрузках, особенно при численном моделировании и подобных задачах. Методы векторной обработки также работают в оборудовании игровых приставок и графических ускорителях.
Вероятностное программирование (Probabilistic programming) — это парадигма программирования, в которой задаются вероятностные модели, а вывод для этих моделей выполняется автоматически. Он представляет собой попытку объединить вероятностное моделирование и традиционное программирование общего назначения, чтобы упростить первое и сделать его более широко применимым. Его можно использовать для создания систем, помогающих принимать решения в условиях неопределенности. Языки программирования, используемые для вероятностного программирования, называются «вероятностными языками программирования» (PPL),.
Взрыв интеллекта (Intelligence explosion) — это термин, придуманный для описания конечных результатов работы над общим искусственным интеллектом, который предполагает, что эта работа приведет к сингулярности в искусственном интеллекте, где «искусственный сверхинтеллект» превзойдет возможности человеческого познания. В интеллектуальном взрыве подразумевается, что самовоспроизводящиеся аспекты искусственного интеллекта каким-то образом возьмут на себя принятие решений людьми. В 1965 году И. Дж. Гуд впервые описал понятие «взрыв интеллекта» применительно к искусственному интеллекту (ИИ): пусть сверхразумная машина будет определена как машина, которая может намного превзойти все интеллектуальные действия любого человека, каким бы умным он ни был. Поскольку проектирование машин является одним из таких видов интеллектуальной деятельности, сверхразумная машина могла бы создавать еще более совершенные машины; тогда, несомненно, произошел бы «взрыв интеллекта», и разум человека остался бы далеко позади. Таким образом, первая сверхразумная машина — это последнее изобретение, которое когда-либо понадобится человеку, при условии, что машина достаточно послушна, чтобы подсказать нам, как держать ее под контролем. Спустя десятилетия в сообществе ИИ утвердилась концепция «взрыва интеллекта», что приведет к внезапному росту «сверхразума» и случайному концу человечества. Известные бизнес-лидеры считают это серьезным риском, большим, чем ядерная война или изменение климата,.
Видеоаналитика (Video analytics) — это технология, использующая методы компьютерного зрения для автоматизированного использования различных данных, на основании анализа отслеживающих изображений, поступающих с видеокамер в режиме реального времени или из архивных записей,.
Виртуализация (Virtualization) — это предоставление набора вычислительных ресурсов или их логическое объединение, абстрагированное от аппаратной реализации, и обеспечивающее при этом логическую изоляцию друг от друга вычислительных процессов, выполняемых на одном физическом ресурсе.
Виртуальный помощник (Virtual assistant) — это программный агент, который может выполнять задачи для пользователя на основе информации, введенной пользователем.
Виртуальная реальность (VR) (Virtual reality, VR) — это смоделированный опыт, который может быть похож на реальный мир или полностью отличаться от него. Приложения виртуальной реальности включают развлечения (например, видеоигры), образование (например, медицинскую или военную подготовку) и бизнес (например, виртуальные встречи). Другие различные типы технологий в стиле VR включают дополненную реальность и смешанную реальность, иногда называемую расширенной реальностью или XR. Также, под Виртуальной реальностью понимают искусственную среду, созданную с помощью программного обеспечения и представленную пользователю таким образом, что пользователь принимает ее как реальную среду. На компьютере виртуальная реальность в основном воспринимается двумя из пяти органов чувств: зрением и слухом. Простейшая форма виртуальной реальности — это трехмерное изображение, которое можно просматривать в интерактивном режиме на персональном компьютере, обычно манипулируя клавишами или мышью, чтобы содержимое изображения перемещалось в каком-либо направлении или увеличивалось или уменьшалось. Более изощренные усилия включают такие подходы, как круглые экраны, настоящие комнаты, дополненные носимыми компьютерами, и тактильные устройства, которые позволяют вам чувствовать отображаемые изображения. Виртуальную реальность можно разделить на: Моделирование реальной среды для обучения и воспитания. Разработка воображаемой среды для игры или интерактивной истории. Язык моделирования виртуальной реальности (VRML) позволяет создателю задавать изображения и правила их отображения и взаимодействия с помощью текстовых операторов языка,.
Внутренняя мотивация (Intrinsic motivation) — в изучении искусственного интеллекта — это мотивация к действию, при том, что информационное содержание, опыт, полученный в результате действия, является мотивирующим фактором. Информационное содержание в этом контексте измеряется в смысле теории информации как количественная оценка неопределенности. Типичной внутренней мотивацией является поиск необычных (удивительных) ситуаций, в отличие от типичной внешней мотивации, такой как поиск пищи. Искусственные агенты с внутренней мотивацией демонстрируют поведение, похожее на исследование и любопытство. Психологи считают, что внутренняя мотивация у людей — это стремление выполнять деятельность для внутреннего удовлетворения — просто для развлечения или вызова.
Внутригрупповая предвзятость (In-group bias) — это предвзятость, при которой люди склонны отдавать предпочтение людям, которые существуют в тех же группах, что и они. Эти группы могут быть сформированы по признаку пола, расы, этнической принадлежности или любимой спортивной команды. Если кто-то входит в нашу «внутреннюю группу», мы с большей вероятностью будем ему доверять. Проблема предвзятости ИИ — одна из самых острых в современном мире, и решения ей пока нет. Системы распознавания лиц плохо работают на лицах афроамериканцев, а ИИ для приема на работу предпочитает нанимать мужчин, нежели женщин.
Возврат (Return) — это сумма всех вознаграждений, которые агент ожидает получить при следовании политике от начала до конца эпизода. Агент учитывает отсроченный характер ожидаемых вознаграждений, дисконтируя вознаграждения в соответствии с переходами состояний, необходимыми для получения вознаграждения.
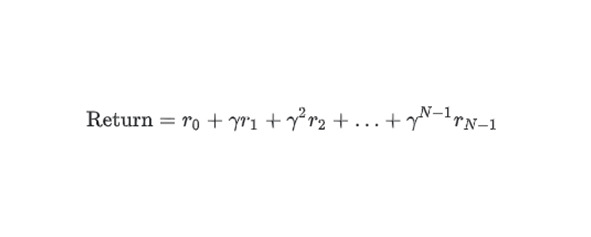
Вознаграждение (Reward) в обучении с подкреплением — это числовой результат выполнения действия в состоянии, определяемом окружающей средой.
Воплощённая когнитивная наука (Embodied cognitive science) — это междисциплинарная область исследований, целью которых является объяснение механизмов, лежащих в основе разумного поведения. Она включает в себя три основных методики: моделирование психологических и биологических систем, которая рассматривает разум и тело как единое целое; формирование основного набора общих принципов разумного поведения; экспериментальное использование роботов в контролируемых условиях.
Восприятие речи (Speech perception) — это процесс, посредством которого звуки языка слышатся, интерпретируются и понимаются. Изучение восприятия речи тесно связано с областями фонологии и фонетики в лингвистике и когнитивной психологии и восприятием в психологии. Исследования в области восприятия речи направлены на то, чтобы понять, как люди-слушатели распознают звуки речи и используют эту информацию для понимания разговорной речи. Исследования восприятия речи находят применение в создании компьютерных систем, способных распознавать речь, в улучшении распознавания речи для слушателей с нарушениями слуха и языка, а также в обучении иностранному языку.
Врата забвения (Forget gate) — это часть ячейки долговременно-кратковременной памяти, которая регулирует поток информации, проходящий через ячейку. Врата забвения поддерживают контекст, решая, какую информацию следует отбросить из ячейки.
Вращательная инвариантность (Rotational invariance) в задаче классификации изображений — это способность алгоритма успешно классифицировать изображения даже при изменении ориентации изображения. Например, алгоритм все еще может идентифицировать теннисную ракетку, направлена ли она вверх, вбок или вниз.
Временная сложность (Time complexity) — это вычислительная сложность, описывающая время, необходимое для выполнения алгоритма. Временная сложность обычно оценивается путем подсчета количества элементарных операций, выполняемых алгоритмом, при условии, что выполнение каждой элементарной операции занимает фиксированное количество времени. Таким образом, время и количество элементарных операций, выполняемых алгоритмом, различаются не более чем на постоянный множитель.
Временной ряд (Time Series) — это последовательность точек данных, записанных в определенное время и проиндексированных в соответствии с порядком их появления.
Временные данные (Temporal data) — это зафиксированные данные, показывающие состояние во времени.
Временные ряды (Time series) — это наблюдения за переменной, сделанные во времени. Многие экономические исследования, такие как Международная финансовая статистика МВФ, представляют собой файлы данных временных рядов. Своего рода временные ряды также могут быть построены на основе перекрестного исследования, если одни и те же вопросы задаются более одного раза в течение времени.
Вспомогательный интеллект (Assistive intelligence) — это системы на основе ИИ, которые помогают принимать решения или выполнять действия.
Встраивание (внедрение слов) (Embedding (Word Embedding)) — это один экземпляр некоторой математической структуры, содержащийся в другом экземпляре, например, группа, являющаяся подгруппой.
Встраивание пространства (Embedding space) — это D-мерное векторное пространство, в которое сопоставляются признаки из векторного пространства более высокой размерности. В идеале пространство вложения содержит структуру, дающую значимые математические результаты; например, в идеальном пространстве вложений сложение и вычитание вложений могут решать задачи аналогии слов. Скалярный продукт двух вложений является мерой их сходства.
Встраивание слов (Word embedding (Vector representation of words)) — это термин (в обработке естественного языка — natural language processing), используемый для представления слов для анализа текста, обычно в форме вектора с действительным знаком, который кодирует значение слова таким образом, что слова, которые находятся ближе в векторном пространстве, становятся ближе по смыслу. Вложения слов можно получить с помощью набора методов языкового моделирования и изучения признаков, в которых слова или фразы из словаря сопоставляются с векторами действительных чисел.
Входной слой (Input layer) — это первый слой в нейронной сети, который принимает входящие сигналы и передает их на последующие уровни.
Вторичный анализ (Secondary analysis) — это процесс пересмотра существующих данных для решения новых вопросов или использования ранее не использовавшихся методов.
Выбор действия (Action selection) — это процесс, включающий алгоритм, как разработанная интеллектуальная система будет реагировать на данную проблему. Обычно это область, изучаемая в психологии, робототехнике и искусственном интеллекте. Выбор действий является синонимом принятия решений и поведенческого выбора. Собранные данные исследуются и разбиваются для того, чтобы можно было адаптировать их к искусственным системам, таким как робототехника, видеоигры и программирование искусственного интеллекта.
Выбор переменных (Feature selection) — это выбор признаков, также известный как выбор переменных, выбор атрибутов или выбор подмножества переменных, представляет собой процесс выбора подмножества соответствующих признаков (переменных, предикторов) для использования в построении модели.
Выборка (Sampling) — это использование при анализе информации не всего объема данных, а только их части, которая отбирается по определенным правилам (выборка может быть случайной, стратифицированной, кластерной и квотной).
Выборка кандидатов (Candidate sampling) — это оптимизация времени обучения, при которой вероятность рассчитывается для всех положительных меток, но только для случайной выборки отрицательных меток. Например, если нам нужно определить, является ли входное изображение биглем или ищейкой, нам не нужно указывать вероятности для каждого примера, не связанного с собакой.
Выбросы (Outliers) — это точки данных, которые значительно отличаются от других, присутствующих в данном наборе данных. Наиболее распространенные причины выбросов в наборе данных: Ошибки ввода данных. Ошибка измерения. Ошибки эксперимента. Преднамеренные ошибки. Ошибки обработки данных. Ошибки выборки. Естественный выброс.
Вывод (Inference) в искусственном интеллекте и машинном обучении — это составление прогнозов путем применения обученной модели к немаркированным примерам.
Выделение признаков (Feature extraction) — это разновидность абстрагирования, процесс снижения размерности, в котором исходный набор исходных переменных сокращается до более управляемых групп признаков для дальнейшей обработки, оставаясь при этом достаточным набором для точного и полного описания исходного набора данных. Выделение признаков используется в машинном обучении, распознавании образов и при обработке изображений. Выделение признаков начинает с исходного набора данных, выводит вторичные значения (признаки), для которых предполагается, что они должны быть информативными и не должны быть избыточными, что способствует последующему процессу обучения машины и обобщению шагов, а в некоторых случаях ведёт и к лучшей человеческой интерпретацией данных.
Выполнение графа (Graph execution) — это среда программирования TensorFlow, в которой программа сначала строит граф, а затем выполняет весь или часть этого графа. Выполнение графа — это режим выполнения по умолчанию в TensorFlow 1.x.
Выполнимость (Satisfiability). В математической логике выполнимость и достоверность — это элементарные понятия семантики. Формула выполнима, если можно найти интерпретацию (модель), которая делает формулу истинной. Формула действительна, если все интерпретации делают ее истинной. Противоположностями этих понятий являются невыполнимость и недействительность, то есть формула невыполнима, если ни одна из интерпретаций не делает формулу истинной, и недействительна, если какая-либо такая интерпретация делает формулу ложной.
Выпрямленный линейный блок (Rectified Linear Unit) — это блок, использующий функцию выпрямителя в качестве функции активации.
Выпуклая оптимизация (Convex optimization) — это процесс использования математических методов, таких как градиентный спуск, для нахождения минимума выпуклой функции. Многие исследования в области машинного обучения были сосредоточены на формулировании различных задач выпуклой оптимизации и более эффективном решении этих проблем.
Выпуклая функция (Convex function) — это функция, в которой область над графиком функции представляет собой выпуклое множество. Прототип выпуклой функции имеет форму буквы U. Строго выпуклая функция имеет ровно одну точку локального минимума. Классические U-образные функции являются строго выпуклыми функциями. Однако некоторые выпуклые функции (например, прямые) не имеют U-образной формы. Многие распространенные функции потерь, являются выпуклыми функциями: L2 loss; Log Loss; L1 regularization; L2 regularization. Многие варианты градиентного спуска гарантированно находят точку, близкую к минимуму строго выпуклой функции. Точно так же многие варианты стохастического градиентного спуска имеют высокую вероятность (хотя и не гарантию) нахождения точки, близкой к минимуму строго выпуклой функции. Сумма двух выпуклых функций (например, L2 loss + L1 regularization) является выпуклой функцией. Глубокие модели никогда не бывают выпуклыми функциями. Примечательно, что алгоритмы, разработанные для выпуклой оптимизации, в любом случае имеют тенденцию находить достаточно хорошие решения в глубоких сетях, даже если эти решения не гарантируют глобальный минимум,.
Выпуклое множество (Convex set) — это подмножество евклидова пространства, при этом, линия, проведенная между любыми двумя точками в подмножестве, остается полностью внутри подмножества.
Выходной слой (Output layer) — это последний слой нейронов в искусственной нейронной сети, который производит заданные выходные данные для программы.
Вычисление (Computation) — это любой тип арифметического или неарифметического вычисления, которое следует четко определенной модели (например, алгоритму).
Вычисления GPU (GPU computing) — это использование графического процессора в качестве сопроцессора для ускорения центральных процессоров для научных и инженерных вычислений общего назначения. Графический процессор ускоряет приложения, работающие на ЦП, разгружая некоторые ресурсоемкие и трудоемкие части кода. Остальная часть приложения по-прежнему работает на процессоре. С точки зрения пользователя, приложение работает быстрее, потомучто оно использует вычислительную мощность графического процессора с массовым параллелизмом для повышения производительности. Это явление известно как «гетерогенные» или «гибридные» вычисления.
Вычислительная задача (Computational problem) — это одна из трех типов математических задач, решение которых необходимо получить численно. Вычислительная задача называется хорошо обусловленной, если малым погрешностям входных данных соответствуют малые погрешности решения и плохо обусловленной, если малым погрешностям входных данных могут соответствовать сильные изменения в решении.
Вычислительная кибернетика (Computational cybernetics) — это интеграция кибернетики и методов вычислительного интеллекта.
Вычислительная математика (Computational mathematics) — это раздел математики, включающий круг вопросов, связанных с производством разнообразных вычислений. В более узком понимании вычислительная математика — теория численных методов решения типовых математических задач. Современная вычислительная математика включает в круг своих проблем изучение особенностей вычисления с применением компьютеров. Вычислительная математика обладает широким кругом прикладных применений для проведения научных и инженерных расчётов. На её основе в последнее десятилетие образовались такие новые области естественных наук, как вычислительная химия, вычислительная биология и так далее.
Вычислительная нейробиология (Computational neuroscience) — это междисциплинарная наука, целью которой является объяснение в терминах вычислительного процесса того, как биологические системы, составляющие нервную систему, продуцируют поведение. Она связывает нейробиологию, когнитивистику и психологию с электротехникой, информатикой, вычислительной техникой, математикой и физикой,.
Вычислительная система (Computing system) — это предназначенные для решения задач и обработки данных (в том числе вычислений) программно-аппаратный комплекс или несколько взаимосвязанных комплексов, образующих единую инфраструктуру.
Вычислительная статистика (Computational statistics) — это применение принципов информатики и разработки программного обеспечения для решения научных задач. Она включает в себя использование вычислительного оборудования, сетей, алгоритмов, программирования, баз данных и других предметно-ориентированных знаний для разработки симуляций физических явлений для запуска на компьютерах. Вычислительная статистика пересекает дисциплины и может даже включать гуманитарные науки,.
Вычислительная теория чисел, также известная как алгоритмическая теория чисел (Computational number theory) — это изучение вычислительных методов для исследования и решения проблем в теории чисел и арифметической геометрии, включая алгоритмы проверки простоты и численной факторизации, поиска решений диофантовых уравнений и явных методов в арифметической геометрии. Теория вычислительных чисел имеет приложения к криптографии, включая RSA, криптографию на эллиптических кривых и постквантовую криптографию, и используется для исследования гипотезы и открытой проблемы теории чисел, включая гипотезу Римана, гипотезу Берча и Суиннертона-Дайера, гипотезу ABC, гипотезу модульности, гипотезу Сато-Тейта и явные аспекты программы Ленглендса,.
Вычислительная химия (Computational chemistry) — это раздел химии, в котором математические методы используются для расчёта молекулярных свойств, моделирования поведения молекул, планирования синтеза, поиска в базах данных и обработки комбинаторных библиотек,,.
Вычислительная эффективность агента или обученной модели (Computational efficiency of an agent or a trained model) — это количество вычислительных ресурсов, необходимых агенту для решения задачи на стадии инференса.
Вычислительная эффективность интеллектуальной системы (Computational efficiency of an intelligent system) — это количество вычислительных ресурсов, необходимых для обучения интеллектуальной системы с определенным уровнем производительности на том или ином объеме задач.
Вычислительные блоки (Computing units) — это блоки, которые работают как фильтр, который преобразовывает пакеты по определенным правилам. Набор команд вычислителя может быть ограничен, что гарантирует простую внутреннюю структуру и достаточно большую скорость работы.
Вычислительные модули (Computing modules) — это подключаемые специализированные вычислители, предназначенные для решения узконаправленных задач, таких, как ускорение работы алгоритмов искусственных нейронных сетей, компьютерное зрение, распознавание по голосу, машинное обучение и другие методы искусственного интеллекта, построены на базе нейронного процессора — специализированного класса микропроцессоров и сопроцессоров (процессор, память, передача данных).
Вычислительный интеллект (Computational intelligence) — это ответвление искусственного интеллекта. Как альтернатива классическому искусственному интеллекту, основанному на строгом логическом выводе, он опирается на эвристические алгоритмы, используемые, например, в нечёткой логике, искусственных нейронных сетях и эволюционном моделировании.
Вычислительный юмор (Computational humor) — это раздел компьютерной лингвистики и искусственного интеллекта, использующий компьютеры для исследования юмора.
Выявление аномалий (также обнаружение выбросов) (Anomaly detection) — это опознавание во время интеллектуального анализа данных редких данных, событий или наблюдений, которые вызывают подозрения ввиду существенного отличия от большей части данных. Обычно аномальные данные характеризуют некоторый вид проблемы, такой как мошенничество в банке, структурный дефект, медицинские проблемы или ошибки в тексте. Аномалии также упоминаются как выбросы, необычности, шум, отклонения или исключения,.
«Г»
Генеративно-состязательная сеть (Generative Adversarial Network) — это алгоритм машинного обучения без учителя, построенный на комбинации из двух нейронных сетей, одна из которых (сеть G) генерирует образцы, а другая (сеть D) старается отличить правильные («подлинные») образцы от неправильных. Так как сети G и D имеют противоположные цели — создать образцы и отбраковать образцы — между ними возникает антагонистическая игра. Генеративно-состязательную сеть описал Ян Гудфеллоу из компании Google в 2014 году. Использование этой техники позволяет, в частности, генерировать фотографии, которые человеческим глазом воспринимаются как натуральные изображения. Например, известна попытка синтезировать фотографии кошек, которые вводят в заблуждение эксперта, считающего их естественными фото. Кроме того, GAN может использоваться для улучшения качества нечётких или частично испорченных фотографий.
Генеративные модели (Generative model) — это семейство архитектур ИИ, целью которых является создание образцов данных с нуля. Они достигают этого, фиксируя распределение данных того типа вещей, которые мы хотим генерировать. На практике модель может создать (сгенерировать) новые примеры из обучающего набора данных. Например, генеративная модель может создавать стихи после обучения на наборе данных сборника Пушкина.
Генеративный ИИ (Generative AI) — это метод ИИ, который изучает представление артефактов из данных и использует его для создания совершенно новых, полностью оригинальных артефактов, сохраняющих сходство с исходными данными.
Генератор (Generator) — это подсистема в генеративно-состязательной сети, которая создает новые примеры.
Генерация естественного языка (Natural language generation, NLG) — это подмножество обработки естественного языка. В то время как понимание естественного языка сосредоточено на понимании компьютерного чтения, генерация естественного языка позволяет компьютерам писать. NLG — это процесс создания текстового ответа на человеческом языке на основе некоторых входных данных. Этот текст также можно преобразовать в речевой формат с помощью служб преобразования текста в речь. NLG также включает в себя возможности суммирования текста, которые генерируют сводки из входящих документов, сохраняя при этом целостность информации.
Генерация кандидатов (Candidate generation) — это первый этап рекомендации. По запросу система генерирует набор релевантных кандидатов.
Генерация речи (Speech generation) — это задача создания речи из какой-либо другой модальности, такой как текст, движения губ и т. д. Также под синтезом речи понимается компьютерное моделирование человеческой речи. Оно используется для преобразования письменной информации в слуховую там, где это более удобно, особенно для мобильных приложений, таких как голосовая электронная почта и единая система обмена сообщениями. Синтез речи также используется для помощи слабовидящим, так что, например, содержимое экрана дисплея может быть автоматически прочитано вслух слепому пользователю. Синтез речи является аналогом речи или распознавания голоса.
Генетический алгоритм (Genetic Algorithm) — это эвристический алгоритм поиска, используемый для решения задач оптимизации и моделирования путём случайного подбора, комбинирования и вариации искомых параметров с использованием механизмов, аналогичных естественному отбору в природе. Генетический алгоритм требует генетического представления решения и функции пригодности для оценки решения.
Генетический оператор (Genetic operator) — это оператор, используемый в генетических алгоритмах для направления алгоритма к решению данной проблемы. Существует три основных типа операторов (мутация, скрещивание и отбор), которые должны работать в сочетании друг с другом, чтобы алгоритм был успешным.
Геномные данные (Genomic data) — этот термин относится к данным генома и ДНК организма. Они используются в биоинформатике для сбора, хранения и обработки геномов живых существ. Геномные данные обычно требуют большого объема памяти и специального программного обеспечения для анализа.
Гетероассоциативная память (Hetero Associative memory) — это память, похожа на сеть автоассоциативной памяти, это также однослойная нейронная сеть. Однако в этой сети входной обучающий вектор и выходные целевые векторы не совпадают. Веса определяются таким образом, чтобы сеть хранила набор шаблонов. Гетероассоциативная сеть носит статический характер, следовательно, в ней не будет нелинейных операций и операций с запаздыванием. Архитектура, как показано на следующем рисунке, архитектура сети гетероассоциативной памяти имеет «n» количество входных обучающих векторов и «m» количество выходных целевых векторов.
Гибридизация человека и машины (Human-machine hybridization) — это технология, позволяющая соединить человеческое тело и технологическую систему. Текущий подход к разработке интеллектуальных систем (например, на основе технологий искусственного интеллекта) в основном ориентирован на данные. Он имеет ряд ограничений: принципиально невозможно собрать данные для моделирования сложных объектов и процессов; обучение нейронных сетей требует огромных вычислительных и энергетических ресурсов; и решения не объяснимы. Современные системы ИИ (основанные на узком ИИ) вряд ли можно считать интеллектом. Это скорее следующий уровень автоматизации человеческого труда. Перспективной концепцией, лишенной вышеуказанных ограничений, является концепция гибридного интеллекта, объединяющая сильные стороны узкого ИИ и возможности человека. Гибридные интеллектуальные системы обладают следующими ключевыми особенностями: Когнитивная интероперабельность — позволяет искусственным и естественным интеллектуальным агентам легко общаться для совместного решения проблемы; Взаимная эволюция (коэволюция) — позволяет гибридной системе развиваться, накапливать знания и формировать общую онтологию предметной области. Ядром гибридизации человеко-машинного интеллекта является функциональная совместимость биологических и технических систем на разных уровнях от физических сигналов до когнитивных моделей.
Гибридные модели (Hybrid models) — это комбинации моделей на основе данных с «классическими» моделями, а также комплексирование различных методов искусственного интеллекта.
Гибридный суперкомпьютер (Hybrid supercomputer) — это вычислительная система, объединяющая ЦП традиционной архитектуры (например, x86) и ускорители, например, на вычислительных графических процессорах.
Гиперпараметр (настройка гиперпараметра) (Hyperparameter) — в машинном обучении — это параметры алгоритмов, значения которых устанавливаются перед запуском процесса обучения. Гиперпараметры используются для управления процессом обучения.
Гипер-эвристика (Hyper-heuristic) — это эвристический метод решения задачи, который стремится автоматизировать, часто путем включения методов машинного обучения, процесс выбора, объединения, генерации или адаптации нескольких более простых эвристик (или компонентов таких эвристик) для эффективного решения задач вычислительного поиска. Одной из мотиваций для изучения гипер-эвристики является создание систем, которые могут обрабатывать классы проблем, а не решать только одну проблему.
Глубина (Depth) — это количество слоев (включая любые встраивающие слои) в нейронной сети, которые изучают веса. Например, нейронная сеть с 5 скрытыми слоями и 1 выходным слоем имеет глубину 6.
Глубокая модель (Deep model) — это тип нейронной сети, содержащий несколько скрытых слоев.
Глубокая нейронная сеть (ГНС) (Deep neural network) многослойная сеть, содержащая между входным и выходным слоями несколько (много) скрытых слоёв нейронов, что позволяет моделировать сложные нелинейные отношения. ГНС сейчас всё чаще используются для решения таких задач искусственного интеллекта, как распознавание речи, обработка текстов на естественном языке, компьютерное зрение и т.п., в том числе в робототехнике.
Глубоко разделяемая сверточная нейронная сеть (Depthwise separable convolutional neural network) — это архитектура сверточной нейронной сети, основанная на Inception (раздел с данными на GitHub), но в которой модули Inception заменены свертками, отделяемыми по глубине. Также известен как Xception.
Глубокое обучение (Deep Learning) — это разновидность машинного обучения на основе искусственных нейронных сетей, а также глубокое (глубинное) структурированное или иерархическое машинное обучение, набор алгоритмов и методов машинного обучения (machine learning) на основе различных видов представления данных. Обучение может быть контролируемым, полу контролируемым (semi-supervised) или неконтролируемым. Использование в глубоком обучении рекуррентных нейронных сетей (recurrent neural networks), позволяет эффективно решать задачи в областях компьютерного зрения, распознавания речи, обработки текстов на естественном языке, машинного перевода, биоинформатики и др..
Государство-как-Платформа (State-as-Platform) — это концепция трансформации государственного управления с использованием возможностей, которые нам дают новые технологии. Целевой функцией реализации идеи «Государство-как-Платформа» является благополучие граждан и содействие экономическому росту, основанному на внедрении технологий. В фокусе развертывания Платформы находится гражданин в условиях новой цифровой реальности. Государство должно создать условия, которые помогут человеку раскрыть свои способности, и сформировать комфортную и безопасную среду для его жизни и реализации потенциала, а также для создания и внедрения инновационных технологий,.
Градиент (Gradient) — это вектор, своим направлением указывающий направление наибольшего возрастания некоторой скалярной величины (значение которой меняется от одной точки пространства к другой, образуя скалярное поле), а по величине (модулю) равный скорости роста этой величины в этом направлении.
Градиентная обрезка (Gradient clipping) — это метод, позволяющий справиться с проблемой взрывающихся градиентов путем искусственного ограничения (отсечения) максимального значения градиентов при использовании градиентного спуска для обучения модели.
Градиентный спуск (Gradient descent) — это метод минимизации потерь путем вычисления градиентов потерь по отношению к параметрам модели на основе обучающих данных. Градиентный спуск итеративно корректирует параметры, постепенно находя наилучшую комбинацию весов и смещения для минимизации потерь.
Граница решения (Decision boundary) — это разделитель между классами, изученными моделью в задачах классификации двоичного класса или нескольких классов.
Граница решения или поверхность решения (в статистико-классификационной задаче с двумя классами) (Decision boundary) — это гиперповерхность, разделяющая нижележащее векторное пространство на два множества, по одному для каждого класса. Классификатор классифицирует все точки на одной стороне границы принятия решения как принадлежащие одному классу, а все точки на другой стороне как принадлежащие другому классу.
Граф (Graph) — это таблица, составленная из данных (тензоров) и математических операций. TensorFlow — это библиотека для численных расчетов, в которой данные проходят через граф. Данные в TensorFlow представлены n-мерными массивами — тензорами.
Граф (абстрактный тип данных) (Graph) — в информатике граф — это абстрактный тип данных, который предназначен для реализации концепций неориентированного графа и ориентированного графа из математики; в частности, область теории графов.
Граф (с точки зрения компьютерных наук и дискретной математики) (Graph) — это абстрактный способ представления типов отношений, например дорог, соединяющих города, и других видов сетей. Графы состоят из рёбер и вершин. Вершина — это точка на графе, а ребро — это то, что соединяет две точки на графе.
Графический кластер (Graphics Processing Cluster, GPC) — это доминирующий высокоуровневый блок, включающий все ключевые графические составляющие.
Графический процессор (Graphical Processing Unit) — это отдельный процессор, расположенный на видеокарте, который выполняет обработку 2D или 3D графики. Имея процессор на видеокарте, компьютерный процессор освобождается от лишней работы и может выполнять все другие важные задачи быстрее. Особенностью графического процессора (GPU), является то, что он максимально нацелен на увеличение скорости расчета именно графической информации (текстур и объектов). Благодаря своей архитектуре такие процессоры намного эффективнее обрабатывают графическую информацию, нежели типичный центральный процессор компьютера.
Графический процессор-вычислитель (Computational Graphics Processing Unit) (ГП-вычислитель cGPU) — это многоядерный ГП, используемый в гибридных суперкомпьютерах для выполнения параллельных математических вычислений; например, один из первых образцов ГП этой категории содержит более 3 млрд транзисторов — 512 ядер CUDA и память ёмкостью до 6 Гбайт.
Графовая база данных (Graph database) — это база, предназначенная для хранения взаимосвязей и навигации в них. Взаимосвязи в графовых базах данных являются объектами высшего порядка, в которых заключается основная ценность этих баз данных. В графовых базах данных используются узлы для хранения сущностей данных и ребра для хранения взаимосвязей между сущностями. Ребро всегда имеет начальный узел, конечный узел, тип и направление. Ребра могут описывать взаимосвязи типа «родитель-потомок», действия, права владения и т. п. Ограничения на количество и тип взаимосвязей, которые может иметь узел, отсутствуют. Графовые базы данных имеют ряд преимуществ в таких примерах использования, как социальные сети, сервисы рекомендаций и системы выявления мошенничества, когда требуется создавать взаимосвязи между данными и быстро их запрашивать.
Графовые нейронные сети (Graph neural networks) — это класс методов глубокого обучения, предназначенных для выполнения выводов на основе данных, описанных графами. Графовые нейронные сети — это нейронные сети, которые можно напрямую применять к графам и которые обеспечивают простой способ выполнения задач прогнозирования на уровне узлов, ребер и графов. GNN могут делать то, что не смогли сделать сверточные нейронные сети (CNN). Также под Графовыми нейронными сетями понимают нейронные модели, которые фиксируют зависимость графов посредством передачи сообщений между узлами графов. В последние годы варианты GNN, такие как сверточная сеть графа (GCN), сеть внимания графа (GAT), рекуррентная сеть графа (GRN), продемонстрировали новаторские характеристики во многих задачах глубокого обучения.
Графы знаний (Knowledge graphs) — это структуры данных, представляющие знания о реальном мире, включая сущности люди, компании, цифровые активы и т.д.) и их отношения, которые придерживаются модели данных графа — сети узлов (вершин) и соединения (ребер/дуг).
Гребенчатая регуляризация (Ridge regularization) — синоним «Регуляризации L2». Термин гребенчатая регуляризация чаще используется в контексте чистой статистики, тогда как регуляризация L2 чаще используется в машинном обучении.
«Д»
Данные (Data) — это информация собранная и трансформированная для определенных целей, обычно анализа. Это может быть любой символ, текст, цифры, картинки, звук или видео.
Данные тестирования (Testing Data) — это подмножество доступных данных, выбранных специалистом по данным для этапа тестирования разработки модели.
Данные ограниченного использования (Restricted-use data) — это данные, которые содержат конфиденциальную информацию (обычно о людях), которая может позволить идентифицировать людей. Наличие конфиденциальной информации в депонированном цифровом контенте представляет собой проблему управления для долгосрочного хранения, чтобы гарантировать, что требования к архивному хранилищу для достижения распределенной избыточности учитывают, например, требования конфиденциальности.
Дартмутский семинар (Dartmouth workshop) — Дартмутский летний исследовательский проект по искусственному интеллекту — так назывался летний семинар 1956 года, который многие считают основополагающим событием в области искусственного интеллекта.
Датамайнинг (Datamining) — это процесс обнаружения и интерпретации значимых закономерностей и структур в исходных данных, которые могут быть использованы для решения сложных бизнес-вопросов и высокоинтеллектуального прогнозирования.
Даунсэмплинг (downsampling) — это уменьшение количества информации в функции для более эффективного обучения модели. Например, перед обучением модели распознавания изображений, субдискретизация изображений с высоким разрешением до формата с более низким разрешением; Обучение на непропорционально низком проценте чрезмерно представленных примеров классов, чтобы улучшить модель обучения на недопредставленных классах.
Движок искусственного интеллекта (Artificial intelligence engine) (также AI engine, AIE) — это движок искусственного интеллекта, аппаратно-программное решение для повышения скорости и эффективности работы средств системы искусственного интеллекта.
Двоичное число (Binary number) — это число, записанное в двоичной системе счисления, в которой используются только нули и единицы. Пример: Десятичное число 7 в двоичной системе счисления: 111.
Двоичный формат (Binary format) — это любой формат файла, в котором информация закодирована в каком-либо формате, отличном от стандартной схемы кодирования символов. Файл, записанный в двоичном формате, содержит информацию, которая не отображается в виде символов. Программное обеспечение, способное понимать конкретный метод кодирования информации в двоичном формате, должно использоваться для интерпретации информации в файле в двоичном формате. Двоичные форматы часто используются для хранения большего количества информации в меньшем объеме, чем это возможно в файле символьного формата. Их также можно быстрее искать и анализировать с помощью соответствующего программного обеспечения. Файл, записанный в двоичном формате, может хранить число «7» как двоичное число (а не как символ) всего в 3 битах (т.е. 111), но чаще используется 4 бита (т.е. 0111). Однако двоичные форматы обычно не переносимы. Файлы программного обеспечения записываются в двоичном формате. Примеры файлов с числовыми данными, распространяемых в двоичном формате, включают двоичные версии IBM файлов Центра исследований цен на ценные бумаги и Национального банка торговых данных Министерства торговли США на компакт-диске. Международный валютный фонд распространяет международную финансовую статистику в смешанном формате и двоичном (упакованно-десятичном) формате. SAS и SPSS хранят свои системные файлы в двоичном формате.
Двоичная, бинарная или дихотомическая классификация (Binary classification) — это задача классификации элементов заданного множества в две группы (определение, какой из групп принадлежит каждый элемент множества) на основе правила классификации.
Двунаправленная языковая модель (Bidirectional language model) — это языковая модель, которая определяет вероятность того, что данный маркер присутствует в заданном месте в отрывке текста на основе предыдущего и последующего текста.
Двунаправленность (Bidirectional) — это термин, используемый для описания системы оценки текста, которая одновременно исследует предшествующий и последующий разделы текста от целевого раздела.
Двусмыссленная фраза (Crash blossom) — это предложение или фраза с двусмысленным значением. Crash blossom представляет серьезную проблему для понимания естественного языка. Например, заголовок «бить баклуши» является Crash blossom, потому что нейронная сеть с пониманием естественного языка может интерпретировать заголовок буквально или образно.
Дедуктивный классификатор (Deductive classifier) — это тип механизма вывода искусственного интеллекта. Он принимает в качестве входных данных набор деклараций на языке кадра об области, такой как медицинские исследования или молекулярная биология. Классификатор определяет, являются ли различные описания логически непротиворечивыми, и если нет, то выделяет конкретные описания и несоответствия между ними.
Дедукция (Deductive Reasoning) — это способ рассуждения и доказательства на основе перехода от более общих положений к частным, один из способов прогнозирования развития и изложения материала; эффективен, когда у исследователя уже накоплен определенный опыт и знания в изучаемой области.
Действие (Action) (в обучении с подкреплением) — это механизм, с помощью которого агент переходит между состояниями среды. Агент выбирает действие с помощью политики.
Декларативное программирование (Declarative programming) — это парадигма программирования, в которой задаётся спецификация решения задачи, то есть описывается ожидаемый результат, а не способ его получения. Противоположностью декларативного является императивное программирование, при котором на том или ином уровне детализации требуется описание последовательности шагов для решения задачи,.
Демографический паритет (Demographic parity) — это метрика справедливости, которая удовлетворяется, если результаты классификации модели не зависят от данного конфиденциального атрибута.
Дерево поведения (Behavior tree) — это ориентированный ациклический граф, узлами которого являются возможные варианты поведения робота. «Ширина» дерева указывает на количество доступных действий, а «длина» его ветвей характеризует их сложность. Деревья поведения имеют некоторое сходство с иерархическими конечными автоматами с тем ключевым отличием, что основным строительным блоком поведения является задача, а не состояние. Простота понимания человеком делает деревья поведения менее подверженными ошибкам и очень популярными в сообществе разработчиков игр.
Дерево проблем (решений) или логическое дерево (Issue tree) — это денотативное (отражающее ситуацию) представление процесса принятия решений, представленное в виде графической разбивки задачи, разделенное на отдельные компоненты по вертикали и горизонтали. Деревья решений в искусственном интеллекте используются для того, чтобы делать выводы на основе данных, доступных из решений, принятых в прошлом. Деревья решений — это статистические алгоритмические модели машинного обучения, которые интерпретируют и изучают ответы на различные проблемы и их возможные последствия. В результате деревья решений знают правила принятия решений в конкретных контекстах на основе доступных данных.
Дерево решений (Decision Tree) — это метод представления решающих правил в иерархической структуре, состоящей из элементов двух типов — узлов (node) и листьев (leaf). В узлах находятся решающие правила и производится проверка соответствия примеров этому правилу по какому-либо атрибуту обучающего множества,,.
Декомпрессия (Decompression) — это функция, которая используется для восстановления данных в несжатую форму после сжатия.
Децентрализованное управление (Decentralized control) — это процесс, при котором существенное количество управляющих воздействий, относящихся к данному объекту, вырабатываются самим объектом на основе самоуправления.
Децентрализованные приложения (Decentralized applications, dApps) — это цифровые приложения или программы, которые существуют и работают в блокчейне или одноранговой (P2P) сети компьютеров, а не на одном компьютере. DApps (также называемые «dapps») находятся вне компетенции и контроля одного органа. DApps, которые часто создаются на платформе Ethereum, можно разрабатывать для различных целей, включая игры, финансы и социальные сети.
Дешифратор (декодер) (Decoder) — это комбинационное устройство с несколькими входами и выходами, у которого определенным комбинациям входных сигналов соответствует активное состояние одного из выходов. Дешифраторы преобразуют двоичный или двоично-десятичный код в унитарный код.
Диагностика (Diagnosis) — это термин, связанный с разработкой алгоритмов и методов, способных определить правильность поведения системы. Если система работает неправильно, алгоритм должен быть в состоянии определить с максимально возможной точностью, какая часть системы дает сбой и с какой неисправностью она сталкивается. Расчет основан на наблюдениях, которые предоставляют информацию о текущем поведении.
Диалоговые системы (Dialogue system) — это компьютерные системы, предназначенные для общения с человеком. Они имитируют поведение человека и обеспечивают естественный способ получения информации, что позволяет значительно упростить руководство пользователя и тем самым повысить удобство взаимодействия с такими системами. Диалоговую систему также называют разговорным искусственным интеллектом или просто ботом. Диалоговая система может в разной степени являться целеориентированной системой (англ. goal/task-oriented) или чат-ориентированной (англ. chat-oriented).
Дизайн-центр (Design Center) — это организационная единица (вся организация или ее подразделение), выполняющая полный спектр или часть работ по созданию продукции до этапа ее серийного производства, а также обладающая необходимыми для этого кадрами, оборудованием и технологиями.
Диктовка (Dictation) — это речевой (голосовой) ввод текста.
Динамическая модель (Dynamic model) — это теоретическая конструкция (модель), описывающая изменение состояний объекта. Она может включать в себя описание этапов или фаз или диаграмму состояний подсистем. Часто имеет математическое выражение и используется главным образом в общественных науках (например, в социологии), имеющих дело с динамическими системами, однако современная парадигма науки способствует тому, что данная модель также имеет широкое распространение во всех без исключения науках, в том числе в естественных и технических. Динамическая модель обучается онлайн в постоянно обновляемой форме. То есть данные непрерывно поступают в модель,.
Динамическая эпистемическая логика (Dynamic epistemic logic, DEL) — это логическая структура, связанная с изменением знаний и информации. Как правило, DEL фокусируется на ситуациях с участием нескольких агентов и изучает, как меняются их знания при возникновении событий.
Дискретная система (Discrete system) — это кибернетическая система, все элементы которой, а также связи между ними (т.е. обращающаяся в системе информация) имеют дискретный характер. Содержит в себе понятие дискретного сигнала. Т.е., это любая система в замкнутом контуре управления в которой используются дискретные сигналы.
Дискретные признаки (Discrete feature) — это количественные признаки, принимающие отдельные, иногда только целочисленные значения. Например, число жителей города, заболевших гриппом за год.
Дискриминатор (Discriminator) — это функциональная группа, выполняющая сравнение двух одноименных входных величин (мгновенных значений или амплитуд, частот, фаз, задержек электрических сигналов; дальностей, направлений, скоростей объектов и т.п.), выходной сигнал которой пропорционален разности значений этих величин. В контуре управления служит датчиком рассогласования своих входных величин, формирующим сигнал ошибки. Это система, которая определяет, являются ли примеры реальными или поддельными.
Дискриминационная модель (Discriminative model) — это модель, предсказывающая метки на основе набора из одного или нескольких признаков. Более формально, дискриминационные модели определяют условную вероятность выхода с учетом характеристик и весов.
Дикий код (Wild code) — это коды, которые не разрешены для конкретного вопроса. Например, если вопрос, в котором указывается пол респондента, имеет задокументированные коды «1» для женского пола и «2» для мужского пола и «9» для «отсутствующих данных», код «3» будет «диким». код, который иногда называют «недокументированным кодом».
Длинный Хвост (Long Tail) означает разнообразную, но малообъемную часть ассортимента продукции. Интернет сделал возможным получение прибыли от продажи продуктов с длинным хвостом. Концепция была представлена Крисом Андерсоном в 2004 году.
Доверенный или надежный искусственный интеллект (Trustworthy Artificial Intelligence, TAI) — это прикладная система искусственного интеллекта, обеспечивающая выполнение возложенных на нее задач с учетом ряда дополнительных требований, учитывающих этические аспекты применения искусственного интеллекта, а также обеспечивающая доверие к результатам работы системы ИИ, которые включают в себя: Достоверность (надежность) и интерпретируемость выводов и предлагаемых решений, полученных с помощью системы и проверенных на верифицированных тестовых примерах. Безопасность как с точки зрения невозможности причинения вреда пользователям системы на протяжении всего жизненного цикла системы, так и с точки зрения защиты от взлома, несанкционированного доступа и других негативных внешних воздействий. Приватность и верифицируемость данных, с которыми работают алгоритмы искусственного интеллекта, включая разграничение доступа и другие связанные с этим вопросы.
Документация (Documentation) как правило, — это любая информация о структуре, содержимом и макете файла данных. Иногда называется «технической документацией» или «кодовой книгой». Документацию можно рассматривать как специализированную форму метаданных.
Документированная информация (Documented information) — это зафиксированная на материальном носителе путем документирования информация с реквизитами, позволяющими определить такую информацию, или в установленных законодательством Российской Федерации случаях ее материальный носитель.
Дистанционное медицинское обслуживание (Remote Medical Care) — это телемедицинский сервис, позволяющий осуществлять постоянный мониторинг состояния пациента и проведение профилактических и контрольных осмотров вне медицинских учреждений. Эта форма ухода стала возможной благодаря использованию мобильных устройств, которые измеряют основные показатели жизнедеятельности. Результаты передаются в Центр дистанционного медицинского обслуживания, где они автоматически анализируются. При обнаружении каких-либо отклонений медицинский персонал связывается с пациентом и вызывает скорую помощь в случае возникновения экстренной ситуации.
Долгая краткосрочная память (Long short-term memory, LSTM) — это разновидность архитектуры рекуррентных нейронных сетей, предложенная в 1997 году Зеппом Хохрайтером и Юргеном Шмидхубером. Как и большинство рекуррентных нейронных сетей, LSTM-сеть является универсальной в том смысле, что при достаточном числе элементов сети она может выполнить любое вычисление, на которое способен обычный компьютер, для чего необходима соответствующая матрица весов, которая может рассматриваться как программа. В отличие от традиционных рекуррентных нейронных сетей, LSTM-сеть хорошо приспособлена к обучению на задачах классификации, обработки и прогнозирования временных рядов в случаях, когда важные события разделены временными лагами с неопределённой продолжительностью и границами. Относительная невосприимчивость к длительности временных разрывов даёт LSTM преимущество по отношению к альтернативным рекуррентным нейронным сетям, скрытым марковским моделям и другим методам обучения для последовательностей в различных сферах применения. Также, — это тип ячейки рекуррентной нейронной сети, используемой для обработки последовательностей данных в таких приложениях, как распознавание рукописного ввода, машинный перевод и субтитры к изображениям. LSTM решают проблему исчезающего градиента, которая возникает при обучении RNN из-за длинных последовательностей данных, сохраняя историю во внутренней памяти на основе новых входных данных и контекста из предыдущих ячеек в RNN.
Дополненная реальность (Augmented reality) — это среда, в реальном времени дополняющая физический мир, каким мы его видим, цифровыми данными с помощью различных устройств (планшетов, смартфонов и др.) и определенного программного обеспечения. Отличие дополненной реальности от виртуальной реальности (virtual reality) в том, что дополненная реальность лишь добавляет отдельные элементы в уже существующий мир.
Дополненный или расширенный интеллект (Augmented Intelligence) — это система искусственного интеллекта, которая помогает человеку в улучшении процесса принятия решений. Основная задача такой системы не заменить человека в решении той или иной прикладной задачи, а оказать ему содействие и помощь, с таем, чтобы расширить возможности человека. Впервые термин «intelligence amplification» («усиление интеллекта») упоминается в книге Уильяма Росса Эшби «Введение в кибернетику» в 1956 году. Расширенный искусственный интеллект улучшает процесс принятия решений человеком как за счет обработки больших объемов данных, которые могут сбить с толку человека, принимающего решения, так и за счет устранения факторов, которые могут искажать или неправильно интерпретировать данные (например, предвзятость или усталость). Современные системы расширенного искусственного интеллекта основываются на машинном обучении, глубоком машинном обучении и анализе больших данных.
Дополнительный или вспомогательный интеллект (Auxiliary intelligence) — это система искусственного интеллекта, которая помогают человеку принимать решения на основе дополнительной информации, получаемой из анализа взаимодействия человека с окружающим его миром. Вспомогательный или дополнительный искусственный интеллект может является полезным дополнением к системе Человеко-ориентированного искусственного интеллекта. Часто вспомогательным искусственным интеллектом называют систему, которая используется специалистами для помощи при решении специализированных задач. Например, врачи используют искусственный интеллект, как вспомогательную систему при диагностике раковых опухолей или врожденных пороков сердца. В машинном обучении существует схожий термин «вспомогательное обучение». Вспомогательное обучение — это подход, при котором в процессе машинного обучения модель определяет наличие объектов, которые не подпадают ни под одну из изученных ею категорий. Название «Вспомогательное обучение» было выбрано из-за введения вспомогательного класса и используется для изучения неизвестных объектов.
Допустимая эвристика (Admissible heuristic) — это эвристическая функция считается допустимой, если она никогда не завышает стоимость достижения цели, т. е. стоимость, которую она оценивает для достижения цели, не превышает наименьшую возможную стоимость. от текущей точки пути.
Достоверность распознавания (Recognition accuracy) — это точность (правильность, достоверность) распознавания. Язык разметки для синтеза речи.
Достоверность данных (Data veracity) — это степень точности или правдивости набора данных. В контексте больших данных важно не только качество данных, но и то, насколько надежными являются источник, тип и обработка данных.
Доступ к информации (Access to information) — это возможность получения информации и ее использования.
Доступ к информации, составляющей коммерческую тайну (Access to information constituting a commercial secret) — это ознакомление определенных лиц с информацией, составляющей коммерческую тайну, с согласия ее обладателя или на ином законном основании при условии сохранения конфиденциальности этой информации.
Драйвер (Driver) — это компьютерное программное обеспечение, с помощью которого другое программное обеспечение (операционная система) получает доступ к аппаратному обеспечению отдельного устройства.
Древо решений (Decision tree) — это модель на основе дерева и ветвей, используемая для отображения решений и их возможных последствий, аналогична блок-схеме.
Дрейф концепций (Concept drift) в предиктивной аналитике и машинном обучении — это статистические свойства целевой переменной, которую модель пытается предсказать, со временем меняются непредвиденным образом. Это вызывает проблемы, потому что прогнозы становятся менее точными с течением времени.
Дрон (Drone) — это беспилотный летательный аппарат.
Дружественный искусственный интеллект (ДИИ) (Friendly artificial intelligence) — это искусственный интеллект (ИИ), который обладает скорее позитивным, чем негативным влиянием на человечество. ДИИ также относится к области исследований, целью которых является создание такого ИИ. Этот термин в первую очередь относится к тем ИИ-программам, которые обладают способностью значительно воздействовать на человечество, таким, например, чей интеллект сравним или превосходит человеческий.
«Е»
Единица анализа (Unit of analysis) — это базовая наблюдаемая сущность, анализируемая в ходе исследования и для которой собираются данные в виде переменных. Хотя единицу анализа иногда называют случаем или «наблюдением», они не всегда являются синонимами. Например, в опросах общественного мнения единицей анализа обычно является один человек, и ответы одного человека на вопросы опроса составляют «кейс». Однако в переписи «случаем» может считаться домохозяйство, поскольку все данные по одному домохозяйству собираются с помощью одного инструмента обследования; «кейс» домохозяйства может содержать различные переменные для разных единиц анализа: физическая жилищная структура, семья в структуре, человек в семье.
Емкость модели (машинного обучения) (Model capacity) — это неофициальный термин, это очень близко (если не синоним) к сложности модели. Это способ рассказать о том, насколько сложную модель или взаимосвязь может выразить модель. Можно было бы ожидать, что модель с большей емкостью сможет смоделировать больше взаимосвязей между большим количеством переменных, чем модель с меньшей емкостью. Проводя аналогию с разговорным определением емкости, вы можете думать о ней как о способности модели учиться на все большем количестве данных, пока она не будет полностью «заполнена» информацией. Существуют различные способы формализовать емкость и вычислить ее числовое значение. Одно из них измерение VC, размерность Вапника-Червоненкиса, — это математически строгая формулировка емкости. Самый распространенный способ оценить емкость модели — подсчитать количество параметров. Чем больше параметров, тем выше емкость в целом.
Естественный язык (Natural language) — это человеческий язык, такой как английский, русский или стандартный мандарин, используемый в повседневном общении людей, в отличие от сконструированного языка, искусственного языка, машинного языка или языка формальной логики. Также называется обычным языком.
«Ж»
Жадная политика (Greedy policy) — в обучении с подкреплением — это политика, которая всегда выбирает действие с наивысшей ожидаемой отдачей.
«З»
Загрузка сознания (Mind uploading (Whole brain emulation)) — это трансгуманистическая концепция, согласно которой «содержание» человеческого мозга можно представить в виде двоичного кода и загрузить на компьютер. Загрузка разума, также известная как эмуляция всего мозга (whole brain emulation, WBE), представляет собой теоретический футуристический процесс сканирования физической структуры мозга, достаточно точного для создания имитации психического состояния (включая долговременную память и «я») и передачи или копирование на компьютер в цифровом виде. Затем компьютер будет запускать симуляцию обработки информации мозгом, чтобы он реагировал, по существу, так же как исходный мозг, и испытывал разумный сознательный разум.
Задача «последовательность к последовательности» (Sequence-to-sequence task) — это задача, которая преобразует входную последовательность маркеров в выходную последовательность маркеров.
Закон Мура (Moore’s Law) — это эмпирическое наблюдение, изначально сделанное Гордоном Муром, согласно которому количество транзисторов, размещаемых в кристалле интегральной схемы, удваивается каждые 24 месяца, а стоимость компьютеров уменьшается вдвое. Другой принцип закона Мура гласит, что рост количества микропроцессоров экспоненциальный.
Закрытый словарь (Closed dictionary) в системах распознавания речи — это словарь с ограниченным количеством слов, на который настроена система распознавания и который не может пополняться пользователем.
Запись Big O notation (Big O notation) — это математическая запись, описывающая предельное поведение функции, когда аргумент стремится к определенному значению или к бесконечности. Это член семейства обозначений, изобретенных Полом Бахманом, Эдмундом Ландау и другими, которые вместе называются обозначениями Бахмана-Ландау или асимптотическими обозначениями.
Запись (Record) в зависимости от контекста «запись» этот термин может относиться к физической или логической записи.
Защита данных (Data protection) — это процесс защиты данных, который включает в себя взаимосвязь между сбором и распространением данных и технологий, общественным восприятием и ожиданием конфиденциальности, а также политическими и правовыми основами, связанными с этими данными. Он направлен на достижение баланса между индивидуальными правами на неприкосновенность частной жизни, но при этом позволяет использовать данные в деловых целях.
Здравомыслящий искусственный интеллект (Artificial Intelligence of the Commonsense knowledge) — это одно из направлений развития искусственного интеллекта, которое занимается моделированием способности человека анализировать различные жизненные ситуации и руководствоваться в своих действиях здравым смыслом. Здравый смысл — это накопленная совокупность общепринятых знаний и взглядов, представлений, форм мышления — о движущих силах природы и общества, взаимоотношениях людей; помимо знаний включает ценности, убеждения, регуляторы практической деятельности, моральные и правовые нормы, элементы религиозного опыта, художественно-эстетические оценки действительности.
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.