
Бесплатный фрагмент - Генеративный искусственный интеллект #Forge&flux
Учебное пособие для школьников старших классов и студентов первых курсов вузов

Предисловие
Дорогие друзья!
У вас в руках интересная и очень полезная книга! С ее помощью вы сможете научиться делать удивительные изображения из мира реальности и фантазии. Но не только. Первые вводные главы помогут вам разобраться в мире технологий под общим названием «искусственный интеллект».
Еще совсем недавно, я очень не любил использовать это словосочетание «искусственный интеллект». По моему мнению те компьютерные технологии, которых в обществе, в прессе стали называть «искусственным интеллектом» не тянули на звание интеллекта. Не выдерживали они конкуренции с человеком, его знаниями, навыками, умственными способностями, что, по-моему, и составляет смысл слова «интеллект».
Примирило меня с этим термином чье-то меткое замечание, что «искусственный интеллект» — это просто торговое наименование комплекса программных алгоритмов, имитирующих деятельность человеческого мозга тем или иным способом для решения практических задач.
В начале этой книги дана очень подробное описание и классификация терминов, описывающих эти алгоритмы и системы, указана область их применимости, и даны практические рекомендации по их использованию.
Но самое главное в этой книге — конечно рассказ как самому делать удивительные изображения. Фактически это пошаговая инструкции, как начать эту работу, как получить первые результаты, как улучшать ранее созданные картинки. Другими словами, перед вами методическое руководство (методичка) по-модному сегодня направлению под названием промпт-инжиниринг (prompt engineering). Конечно, не во всех его проявлениях, а только для генерации изображений, но ценность то в том, что подходы в целом похожи и при генерации текстов, музыки или видео!
С учетом развития технологий, проникновения современных алгоритмов в различные области человеческой деятельности, очень важно уметь пользоваться этими системами. Именно это умение будет определять скорость и стоимость разработок, будь то статья, видеоклип или техническое устройство. Научившись и поняв логику составления запросов к моделям искусственного интеллекта, пусть и на примере генерации изображений, будущий пользователь сможет относительно быстро освоить и другие типы задач, что поможет ему повысить эффективность в своей практической деятельности.
Ну и в качестве вишенки на торте и ориентира, в конце, приведен альбом впечатляющих изображений, подготовленных автором. И за это ему отдельное спасибо!
Гордин Михаил Валерьевич, кандидат технических наук, член Совета при Президенте Российской Федерации по науке и образованию, ректор МГТУ им. Н. Э. Баумана.
Рецензии
«Цифровые технологии все шире и глубже входят в нашу жизнь. Они меняют наше восприятие. Позволяют по-новому понять и увидеть многое в окружающем мире, в различных областях науки и техники. Человек (ребенок) сначала воспринимает мир в образах и звуках. А уже потом начинает соотносить им различные слова и понятия. Став старше, он уже и абстрактные понятия, например вселенная, может представлять как зрительные образы. Выдающийся авиаконструктор А. Н. Туполев говорил, что «Хорошо летать могут только красивые самолеты». Но для этого нужно мысленно представлять то, что хочешь создать. А в медицине, например, не только смотреть и слушать, но нередко и представлять услышанное в образах. Таковы примеры из совершенно разных областей.
Способность моделировать изображения очень непростая и существенная задача. Технологии искусственного интеллекта, методы машинного обучения, способны сегодня на это по нашим запросам. Хотя получить желаемое или удовлетворительное изображение можно только в том случае, когда имеется осмысленное понимание запрашиваемого у искусственного интеллекта. Знакомство с этим, чему может помочь, поспособствовать учебник А. Ю. Чесалова, является важным фактором познания.»
— Кобринский Борис Аркадьевич, доктор медицинских наук, профессор, заслуженный деятель науки Российской Федерации, заведующий отделом систем интеллектуальной поддержки принятия решений ФИЦ «Информатика и управление» РАН, соруководитель магистерской программы «Интеллектуальные технологии в медицине» на факультете ВМК МГУ им. М. В. Ломоносова, профессор кафедры медицинской кибернетики и информатики РНИМУ им. Н. И. Пирогова, председатель Научного совета российской ассоциации искусственного интеллекта.
«Учебник для школьников и студентов младших курсов ВУЗов известного специалиста в области разработки и внедрения цифровых технологий А. Ю. Чесалова посвящён актуальной теме применения систем генеративного искусственного интеллекта, который открывает широкие возможности для решения творческих задач в различных областях человеческой деятельности. В учебнике в доходчивой форме рассматриваются практические вопросы графического моделирования изображений с использованием популярной программы Stable Diffusion WebUI Forge. Данный учебник безусловно вызовет интерес у молодых исследователей возможностей генеративного искусственного интеллекта и будет способствовать развитию практических навыков использования интеллектуальных технологий.»
— Тельнов Юрий Филиппович, доктор экономических наук, профессор, заведующий кафедрой Прикладной информатики и информационной безопасности РЭУ им. Г. В. Плеханова, член Научного совета Российской ассоциации искусственного интеллекта.
«Технологии искусственного интеллекта сейчас находятся на пике интересов пользователей к ним. И кажется, что они могут все. Но правильно понять их возможности, оценить не предполагаемый, а реальный эффект позволит системно изложенный материал данной монографии.»
— Пролетарский Андрей Викторович, доктор технических наук, профессор, руководитель научно-учебного комплекса «Информатика и системы управления», заведующий кафедрой «Компьютерные системы и сети» МГТУ им. Н. Э. Баумана.
«Эффективная визуализирующая репрезентация аналитического продукта в доступной адресату-потребителю форме, комфортной для него в восприятии, усвоении и понимании, — является важным залогом понимания представляемых результатов аналитической работы. Этим определяется высокое значение новейших технологий генеративного искусственного интеллекта, способных создавать сложные иллюстративные образы по последовательностям текстовых запросов оператора. Настоящее издание осуществляет грамотное погружение читателя в мастерство оперирования такими ресурсами.»
— Понкин Игорь Владиславович, доктор юридических наук, профессор, профессор кафедры государственного и муниципального управления Института государственной службы и управления Президентской академии.
Введение
Прошел всего год с того момента, когда я закончил работу над книгой «Невероятный искусственный интеллект Easy Diffusion 3.0». В ней я высказал свое мнение о том, что: «Постичь мир удивительного искусственного интеллекта возможно только тогда, когда мы с вами сможем увидеть положительные результаты его работы, созданные при нашем непосредственном участии. Эти результаты должны быть понятны и объяснимы каждому человеку, а также они должны быть этичны, непредвзяты и не нарушать закон».
Сейчас мое мнение осталось прежним, лишь с небольшой поправкой на то, что мы должны с вами, помимо всего прочего, получать максимальное удовлетворение от раскрытия наших интеллектуальных и творческих потенциалов, реализованных в совместной работе с искусственным интеллектом. Согласитесь, когда мы занимаемся любимой работой — эта работа вдвойне эффективнее и полезнее для нас и окружающих нас людей.
Как вы уже знаете, на сегодняшний день генеративный искусственный интеллект может делать многое, например написать текст нового стихотворения или даже целого рассказа, воспроизвести его различными голосами знаменитых актеров, написать новую музыку или песню, проанализировать большое количество числовых данных и составить прогноз на будущее, играть с нами или сразу с тысячью людей в компьютерные игры. Вообще говоря, его возможности по большей части ограничиваются лишь нашей с вами фантазией и, к сожалению, затратами на их реализацию.
Пожалуй, одной из самых впечатляющих способностей генеративного искусственного интеллекта, на мой взгляд, является его умение создавать уникальные и невероятные изображения. Эти изображения могут быть воплощением трехмерного мира фантастического будущего в компьютерной игре или быть виртуальной симуляцией окружающего нас мира. Изображения могут быть трехмерными или двумерными, а также могут быть выполнены в различных стилях живописи знаменитых художников разных эпох. Но самое интересное то, что на этих изображениях могут появиться существа или предметы, не существующие в нашем мире, которые тем не менее можно материализовать, например, с помощью 3D-принтера.
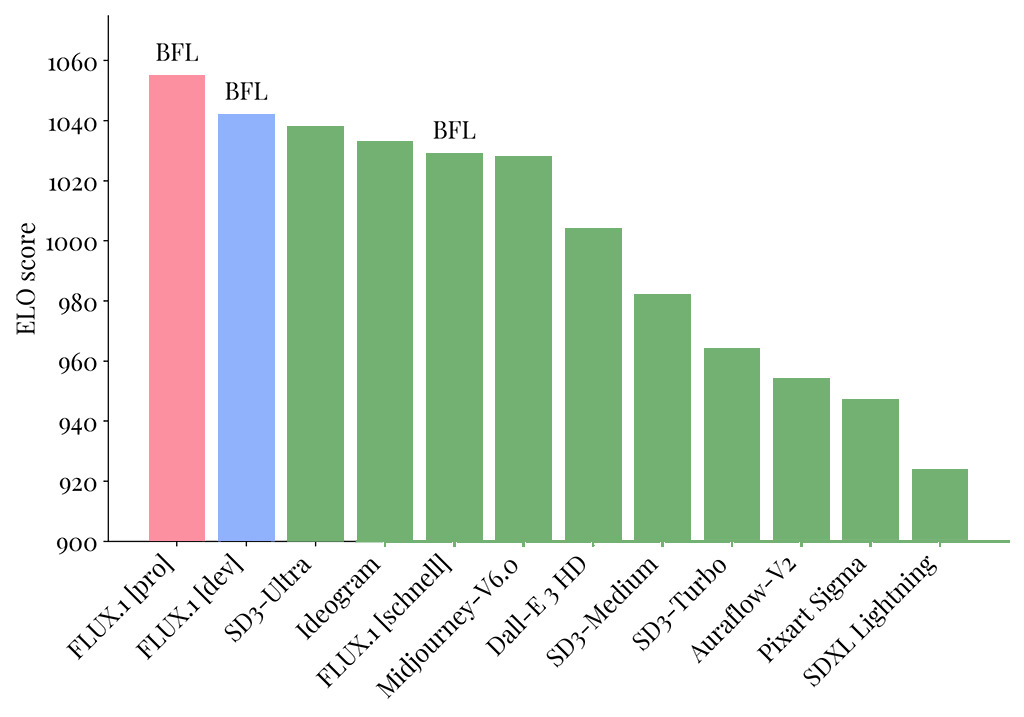
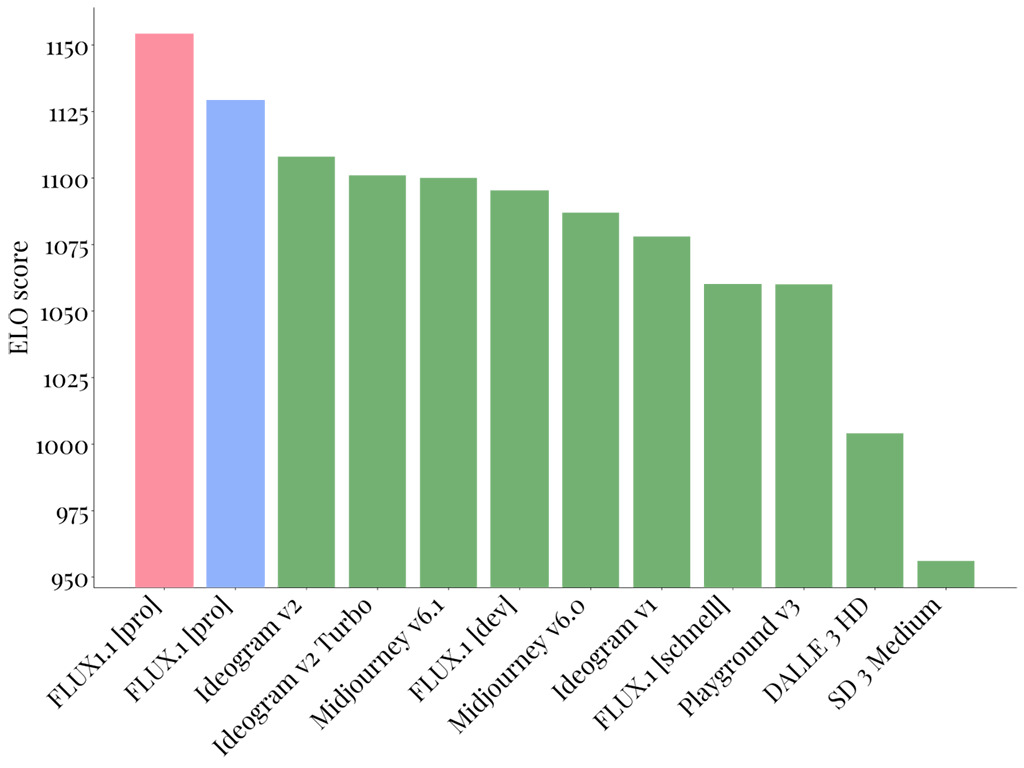
На момент написания и публикации этой книги наиболее популярной моделью, которую поддерживает Stable Diffusion WebUI Forge и при помощи которой создаются уникальные изображения, является FLUX.1, но самой производительной моделью является FLUX1.1 [pro].
В 2024 году модель FLUX.1 стала прорывной технологией в генеративном искусственном интеллекте, оставив позади себя все остальные модели от лидеров рынка. Десятки интернет-сервисов стали рекомендовать ее как наиболее производительную и эффективную при создании изображений. И, как вы уже поняли, именно этой модели уделяется основное внимание в этой книге.
Модель FLUX.1 была создана в 2024 году бывшими инженерами из компании Stability AI, которые занимались разработкой и развитием знаменитой модели Stable Diffusion. Робин Ромбах (Robin Rombach), Андреас Блаттманн (Andreas Blattmann), Доминик Лоренца (Dominik Lorenz) и Патрик Эссер (Patrick Esser) объединили свои усилия в работе над новым проектом FLUX.1 и создали новую компанию Black Forest Lab.
Black Forest Lab предлагает нам три версии модели FLUX.1:
— FLUX.1 [pro] — самая мощная версия реализация коммерческой модели, доступная к использованию через API у партнеров компании или в индивидуальном порядке.
— FLUX.1 [dev] — немного облегченный вариант первой модели не для коммерческого использования. Варианты реализации модели можно найти на сайте huggingface.
— FLUX.1 [schnell] — самая быстрая реализация модели с открытым исходным кодом, которая так и называется «быстрая / нем. schnell». Она предназначена для использования на локальных компьютерах. Исходный код модели можно найти на сайте GitHub. Варианты ее реализации можно найти на сайте huggingface.
По очень смелой оценке инженеров Black Forest Lab, данная модель более производительна, чем все разновидности модели Stable Diffusion, Midjourney и DALL-E.
Но не прошло и полгода, как Black Forest Lab анонсировал выход еще более мощной версии своей модели FLUX1.1 [pro], которая стала значительно эффективнее предыдущей версии.
Модель FLUX1.1 [pro] уже доступна на следующих сервисах: Together.ai, Replicate, fal.ai и Freepik.
С помощью этой книги мы научимся с вами пользоваться системой генеративного искусственного интеллекта Stable Diffusion WebUI Forge и работать с невероятно мощной моделью FLUX.1 как инструментом творчества.
Вы сможете самостоятельно установить, настроить и удалить совершенно бесплатную программу Stable Diffusion WebUI Forge и ее компоненты на свой компьютер, а также подключить к ней различные дополнительные модули, которые значительно расширят ее возможности по созданию и обработке изображений.
Но, и самое главное, управляя различными функциями и параметрами через удобный пользовательский интерфейс Stable Diffusion WebUI Forge, вы научитесь создавать уникальные и совершенно неповторимые изображения, которые сможете использовать в своей учебе, работе или для развлечений.
Приятного вам чтения и продуктивной работы!
Ваш Александр Чесалов.
Несколько важных вопросов
Для кого написана эта книга?
Эта книга написана как учебное пособие для школьников старших классов и студентов первых курсов вузов, а также для всех тех, кто хочет получить дополнительные знания и опыт по работе с системами генеративного искусственного интеллекта.
Не имеет никакого значения, какой у вас опыт работы с компьютером. Не важно, насколько вы погружены в тему искусственного интеллекта, не важно, владеете ли вы навыками программирования, имеет значение только ваше желание познавать новое и создавать невероятное. Для обучения достаточно базового уровня английского языка и знаний компьютера.
Книга, которую вы держите в руках, является учебным пособием по работе с системой генеративного искусственного интеллекта Stable Diffusion WebUI Forge, при помощи которой вы научитесь создать красивые фотореалистичные изображения из текстовых описаний и других графических изображений.
Какая цель книги?
Книга ориентирована на то, чтобы максимально быстро погрузить читателя в предметную область и дать возможность также быстро приступить к практическим занятиям и получению конкретных знаний и результатов.
Основной подход изложения материала в книге — это знания через опыт!
Книга не посвящена описанию всех функциональных возможностей и настроек Stable Diffusion WebUI Forge, потому что это учебник по практической работе с системой генеративного искусственного интеллекта, а не справочник по функциям и настройкам программы.
В свете всего вышесказанного цель книги — передача вам практических и полезных знаний, которые помогут реализовать ваши самые смелые идеи и раскрыть в вас новые творческие потенциалы.
Почему в названии книги используется хештег #FORGE&FLUX?
Я придумал хештег «#FORGE&FLUX», который действительно стал частью названия этой книги. Это было сделано потому, что многие издатели требуют от авторов книг подтверждения использования наименования программы в заголовке книги от разработчиков-правообладателей таких программ. Другими словами, чтобы использовать «Stable Diffusion WebUI Forge» в названии книги, мне нужно разрешение от разработчика. Поэтому и был придуман такой хештег, который позволил обойтись без ненужных формальностей.
Для другой своей книги «Невероятный искусственный интеллект Easy Diffusion 3.0» я такое разрешение от разработчика получил, но это заняло немало времени.
Что означают английские слова в названиях глав книги?
В названиях глав приводятся оригинальные наименования разделов интерфейсов, моделей или сервисов, которые используются в программе Stable Diffusion WebUI Forge и с которыми мы будем с вами работать. Дополнительный перевод на русском языке не приводится по причине того, что названия глав в содержании книги стали бы очень длинными. Но в самой главе все переводы присутствуют.
Например, название главы «Урок 1. Txt2img: пишем правильный запрос» означает то, что мы приступаем к первому уроку, на котором будем изучать написание правильного запроса в интерфейсе Txt2img.
Кому принадлежат права на изображения, созданные при помощи искусственного интеллекта?
Чтобы ответить на этот вопрос, приведу конкретный пример.
На то, чтобы написать эту книгу, у меня ушло шесть месяцев. За это время был выполнен огромный объем работы: изучено много источников информации; самостоятельно приобретены новые знания и опыт; потрачены недели на работу по созданию уникальных изображений; дни, ночи, выходные ушли на написание и редактирование текста. И самое главное, все это нужно было грамотно «упаковать» в книгу простым и доступным языком.
Исходя из личного опыта, я считаю, что процесс создания изображений при помощи систем генеративного искусственного интеллекта является не только творческим, но и интеллектуальным, и эмоциональным процессом. Этот процесс требует от человека высокой степени погружения в предметную область исследований, высокой самоотдачи, концентрации и работоспособности. На сегодняшний день и в ближайшие десятилетия ни один искусственный интеллект не способен и не будет способен на такое.
Когда меня спрашивают: а кому принадлежат результаты интеллектуальной собственности на подобные цифровые произведения? Я всегда отвечаю однозначно — человеку. Система генеративного искусственного интеллекта — это лишь инструмент воплощения творческих, технических и иных способностей человека. Любые спекуляции на тему, что искусственный интеллект — это нечто живое, являются фантазиями одних людей и некомпетентностью других.
Где можно познакомиться с другими работами автора?
Результаты работ, созданные при помощи разных систем генеративного искусственного интеллекта (для меня принципиально важным моментом в этом процессе является использование бесплатных систем, которые можно установить на свой компьютер), я опубликовал в книгах:
— «Невероятный искусственный интеллект Easy Diffusion 3.0». С помощью этой книги и системы генеративного искусственного интеллекта Easy Diffusion 3.0 вы научитесь создавать уникальные и неповторимые изображения, которые сможете использовать в своей учебе или для развлечений. Книга содержит познавательную информацию о существующих видах искусственного интеллекта и прекрасный альбом из более чем ста иллюстраций.
— «Сказки старой Твери: фауна лесных духов». Этот альбом иллюстраций позволит вам и вашим детям осуществить головокружительное путешествие в яркий мир сказочных образов. В нем вы увидите более 300 потрясающих изображений невероятных животных сказочного леса, которых, к сожалению, невозможно встретить в нашем реальном мире.
— «Сказки старой Твери: ночь лесных духов». Этот альбом иллюстраций не только история о творчестве и технологиях, но и глубокое погружение в яркий мир образов славянской мифологии, которое позволит читателю увидеть древних богов и духов в новом свете.
— «Сказки старой Твери: черти». Этот альбом из более 300 невероятно красивых иллюстраций позволит вам погрузиться в сказочную атмосферу мифических существ. Возможности искусственного интеллекта и творческий потенциал человека позволили воплотить в этой книге в реальность собирательные образы чертей и представить их фантастические и фотореалистичные изображения.
Об авторе

Александр Юрьевич Чесалов родился 10 февраля 1977 года в городе Тверь, Российская Федерация.
Экономист по образованию со специализацией «Информационные системы в экономике». Окончил с отличием Тверской Государственный Технический Университет. Защитил докторскую диссертацию на тему «Методология определения операционных характеристик и рациональной структуры региональных распределенных сервисных сетей передачи, обработки и хранения данных».
Имеет различные сертификаты в области ИТ: IBM Professional certificate foundations of AI; IBM Professional certificate Essential Technologies for Business; Rutgers the State University of New Jersey: New Technologies for Business Leaders; University of London; Deeplearning.ai; Microsoft Azure; BSI ISO/IEC 27001; IBM DB2; IBM Lotus Domino и другие.
Александр Юрьевич ведет активную экспертную деятельность. Он является членом Экспертного совета при Комитете Государственной Думы по науке и высшему образованию по вопросам развития информационных технологий в сфере образования и науки, а также членом Российской ассоциации искусственного интеллекта (РАИИ).
Автор более двадцати книг по информационным технологиям, включая: «Моя цифровая реальность»; «Цифровая трансформация»; «Цифровая экосистема Института омбудсмена: концепция, технологии, практика»; «Как создать центр искусственного интеллекта за 100 дней», «Глоссариум по искусственному интеллекту: 2500 терминов», «Невероятный искусственный интеллект Easy Diffusion 3.0», и многих других. Опубликовал научно-исследовательскую работу (монографию) на тему «Методология построения распределенных сетей передачи, обработки и хранения данных» в двух томах.
Часть 1. Немного теории
Что такое генеративный искусственный интеллект?
Знакомство с невероятным миром генеративного искусственного интеллекта мы должны начать с самого простого и важного — с определения, что же такое «искусственный интеллект».
Термин искусственный интеллект (англ. Artificial Intelligence, AI) появился уже очень давно. Впервые он был введен ученым и изобретателем Джоном Маккарти в 1956 году,.
На сегодняшний день ученые, инженеры, маркетологи, программисты и другие специалисты из разных областей экономики используют совершенно разные определения термина «искусственный интеллект». Это связано, прежде всего, с тем, что искусственный интеллект широко применяется в различных сферах человеческой деятельности в различных отраслях экономики.

Например, искусственный интеллект используют в образовании, медицине, государственном управлении, финансах, промышленности, автомобилестроении, космонавтике и многих других направлениях. В каждом из этих направлений есть свои уникальные особенности его развития или специализация его применения.
Так что же такое искусственный интеллект?
Искусственный интеллект (ИИ) — это прежде всего компьютерная программа, написанная человеком (программистом, инженером, ученым или другим специалистом), которая чаще всего имитирует поведение или умственную деятельность человека или какого-либо другого живого существа, живущего на нашей планете.
Наличие и само существование искусственного интеллекта неразрывно и тесно связано с компьютерами, новыми информационными, вычислительными, сетевыми и другими технологиями.
В том случае, когда для обеспечения работы искусственного интеллекта требуются большие вычислительные мощности современных суперкомпьютеров и набор различных вспомогательных программных продуктов, о нем говорят как о сочетании технических и технологических решений, основная задача которых заключается в обеспечении высокого уровня «интеллекта» такой системы.
Изначально искусственный интеллект обучают на различных видах данных. Этот процесс обучения называется машинным обучением (Machine Learning), а данные называют «большими данными» (Big Data).
Машинное обучение (Machine Learning, ML) — это область исследования, которая дает компьютерам возможность учиться без явного программирования. Также под машинным обучением понимают технологии автоматического обучения алгоритмов искусственного интеллекта распознаванию и классификации на тестовых выборках объектов для повышения качества распознавания, обработки и анализа данных, прогнозирования. Также машинное обучение определяют как одно из направлений (подмножеств) искусственного интеллекта, благодаря которому воплощается ключевое свойство интеллектуальных компьютерных систем — самообучение на основе анализа и обработки больших разнородных данных. Чем больше объем информации и ее разнообразие, тем проще искусственному интеллекту найти закономерности и тем точнее будет получаемый результат,,,.
Глубокое обучение (Deep Learning) — это разновидность машинного обучения на основе многослойных искусственных нейронных сетей, а также набор алгоритмов и методов машинного обучения на основе различных видов представления данных. Обучение может быть контролируемым, полуконтролируемым или неконтролируемым. Использование в глубоком обучении рекуррентных нейронных сетей позволяет эффективно решать задачи в областях компьютерного зрения, распознавания речи, обработки текстов на естественном языке, машинного перевода, биоинформатики и др..
Большие данные (Big Data) — это термин для наборов цифровых данных. Большой размер данных и их сложность требует значительных вычислительных мощностей компьютеров и специальных программных инструментов для их анализа и представления. К большим данным относят массивы числовых данных, изображения, аудио- и видеофайлы. Существуют структурированные и неструктурированные данные.
Сегодня ученые и инженеры, совершенствуя различные технологии, стремятся создать самообучаемые и автономные системы искусственного интеллекта, которые должны по своим возможностям приблизиться к интеллектуальным и функциональным возможностям человека.
С точки зрения ученых, искусственный интеллект — это компьютерная система, основанная на комплексе научных и инженерных знаний, а также технологий создания интеллектуальных машин, программ, сервисов и приложений, имитирующая мыслительные процессы человека или живых существ, способная с определенной степенью автономности воспринимать информацию, обучаться и принимать решения на основе анализа больших массивов данных,.
С точки зрения инженеров-программистов, искусственный интеллект — это область информатики, объединяющая вычислительные технологии с надежными наборами данных, в рамках которой разрабатываются компьютерные программы для выполнения задач, способных имитировать человеческий интеллект — обнаруживать смысл, обобщать и делать выводы, выявлять взаимосвязи и обучаться с учетом накопленного опыта,,.
Технологии искусственного интеллекта — это технологии, основанные на использовании искусственного интеллекта, включая компьютерное зрение, обработку естественного языка, распознавание и синтез речи, интеллектуальную поддержку принятия решений и перспективные методы искусственного интеллекта.
Определение термина «искусственный интеллект» неразрывно связано с определением «система искусственного интеллекта».
Система искусственного интеллекта — это компьютерная программа, которая представляет собой реализацию новых технологий обработки информации с целью поиска, анализа и синтеза данных из окружающего нас мира для получения о нем новых знаний и решения на их основе различных жизненно важных задач. Система искусственного интеллекта включает в себя модели и алгоритмы, обеспечивающие ее способность обучения и представления (визуализации) новых данных в виде текста, чисел, аудио, видео или изображений.
Нужно отметить, что классификаций систем искусственного интеллекта достаточно много. Чаще всего используют следующую классификацию:
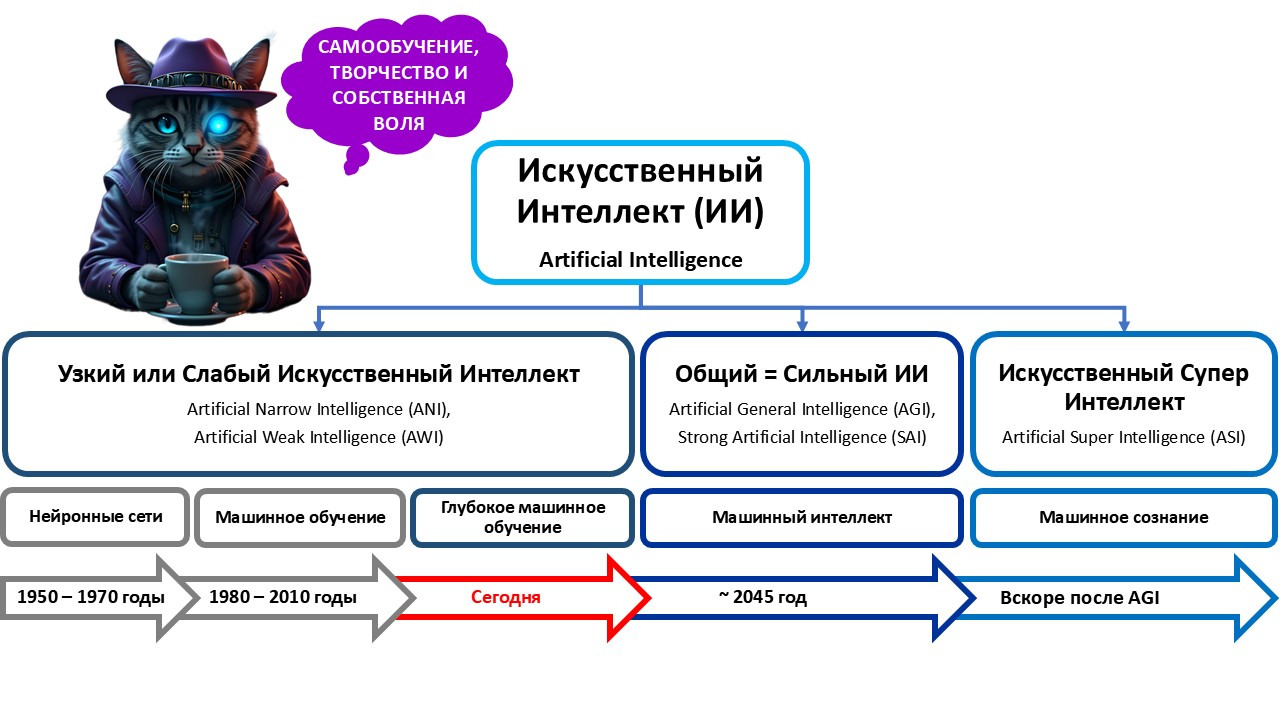
На сегодняшний день искусственный интеллект объединяет в себе сочетание машинного обучения (глубокое обучение и обучение с подкреплением), машинного мышления (планирование, составление графиков, представление знаний, поиск и оптимизацию), вычислительные технологии и суперкомпьютеры, а также робототехнику (контроль, восприятие, датчики и исполнительные механизмы, а также интеграцию всех других технологий в киберфизические системы).
Узкий искусственный интеллект (Artificial Narrow Intelligence, ANI) — это искусственный интеллект, обученный и умеющий выполнять эффективно только определенные узкоспециализированные задачи. Слабый искусственный интеллект является самым распространенным вариантом применения технологий искусственного интеллекта, к которым, прежде всего, относят так называемое «машинное обучение» и «глубокое машинное обучение».
Современные системы узкого искусственного интеллекта запрограммированы на выполнение одной комплексной задачи за раз, извлекая информацию из определенного набора данных. Вся их работа чаще всего сводится к постоянному выполнению однотипных задач с целью получения наилучшего результата в узкой области деятельности,.
К слабому искусственному интеллекту относят: системы распознавания изображений и лиц, чат-боты, разговорных помощников, беспилотные автомобили, рекомендательные и аналитические информационные системы и так далее.
Всем нам знакомые Яндекс Алиса, Apple Siri, Amazon Alexa или суперкомпьютер IBM Watson относятся также, как это ни странно, к узкому или слабому искусственному интеллекту.

Все версии программы ChatGPT, созданной компанией OpenAI, которая способна писать не только посты в интернете, но и создавать собственные литературные произведения, также относятся к узкому искусственному интеллекту.
Программа Stable Diffusion WebUI Forge, которую мы изучаем в этой книге, является системой слабого и узкоспециализированного искусственного интеллекта. Перед этой системой мы ставим задачу — создать для нас новое уникальное изображение из нашего описания или из другого изображения, и Stable Diffusion WebUI Forge решает эту задачу.
Так почему все-таки искусственный интеллект называют слабым?
Слабый искусственный интеллект, каким бы он ни казался «умным» или «сильным», на сегодняшний день не может сравниться с возможностями и потенциалом человеческого интеллекта. Он не обладает волей и не способен на творчество. Слабый искусственный интеллект не способен функционировать самостоятельно, не способен к самообслуживанию, саморазвитию, самосовершенствованию, размножению и к взаимодействию с другими системами искусственного интеллекта, как это делают люди.
Несмотря на все это, у такого вида искусственного интеллекта есть много неоспоримых преимуществ, которые заключается в том, что он способен выполнять конкретные узкоспециализированные задачи очень быстро, качественно и точно, порой даже лучше, чем сам человек. Там, где человек может сильно устать, искусственный интеллект может помочь ему выполнить работу самостоятельно в течение долгого времени. Совместная работа человека и искусственного интеллекта очень сильно сказывается на производительности и эффективности выполняемой работы. Описанный процесс очень часто называют «автоматизацией рутинных задач», который значительно облегчает нашу с вами повседневную жизнь.
Использование слабого искусственного интеллекта дает нам больше времени на саморазвитие, отдых и на достижение новых целей.
Общий искусственный интеллект (Artificial General Intelligence) — это прикладная система искусственного интеллекта, технологии и алгоритмы которой могут выполнять значительное число задач анализа данных, принятия на их основе решений и их реализация, обеспечивающая имитацию интеллектуальных способностей человека и объяснимость предлагаемых человеку вариантов решений, воспроизводя и иногда превышая широкий спектр когнитивных и интеллектуальных способностей человека, включая интерпретацию внешних данных и воздействий и извлечение из них смыслов, использование полученных знаний для обучения, планирования и принятия решений в условиях неопределенности и достижения конкретных целей и задач при помощи гибкой адаптации к изменяющимся условиям и взаимодействию с внешней средой.
Другими словами, сильный искусственный интеллект — это интеллект, не отличимый от человеческого, обладающий самосознанием. Он способен видеть, слышать, учиться, решать задачи, планировать и самосовершенствоваться, а самое главное, он имеет воображение и способен к творчеству.
Общий искусственный интеллект и искусственный интеллект на уровне человека (Human Level Machine Intelligence) — это синонимы сильного искусственного интеллекта. Оба термина обозначают степень развития искусственного интеллекта на уровне человека.
На сегодняшний день сильный или общий искусственный интеллект существует только как теоретическая концепция. Некоторые ученые предполагают, что ее практическая реализация случится не ранее 2045 года. Тем не менее среди большого числа ученых и практиков существует устойчивое мнение, что все, даже самые современные и совершенные системы искусственного интеллекта, которые существуют на сегодняшний день, являются «слабым ИИ», а прогнозы о том, что к 2045 году будет создан сильный ИИ, являются мифом. Причина такому мнению — это сверхсложность устройства нашего головного мозга с точки зрения создания подобного ему суперкомпьютера, который хоть сколь-нибудь смог приблизиться по своей вычислительной мощности к человеческому мозгу. Возможно, в ближайшем будущем прорыв будет осуществлен в области квантовых компьютеров и вычислений, который позволит приблизиться к созданию сильного искусственного интеллекта.
Искусственный сверхинтеллект (Artificial Super Intelligence, ASI) — это термин, который обозначает наивысшую степень развития искусственного интеллекта, превосходящую человеческие возможности во всех аспектах его жизнедеятельности.
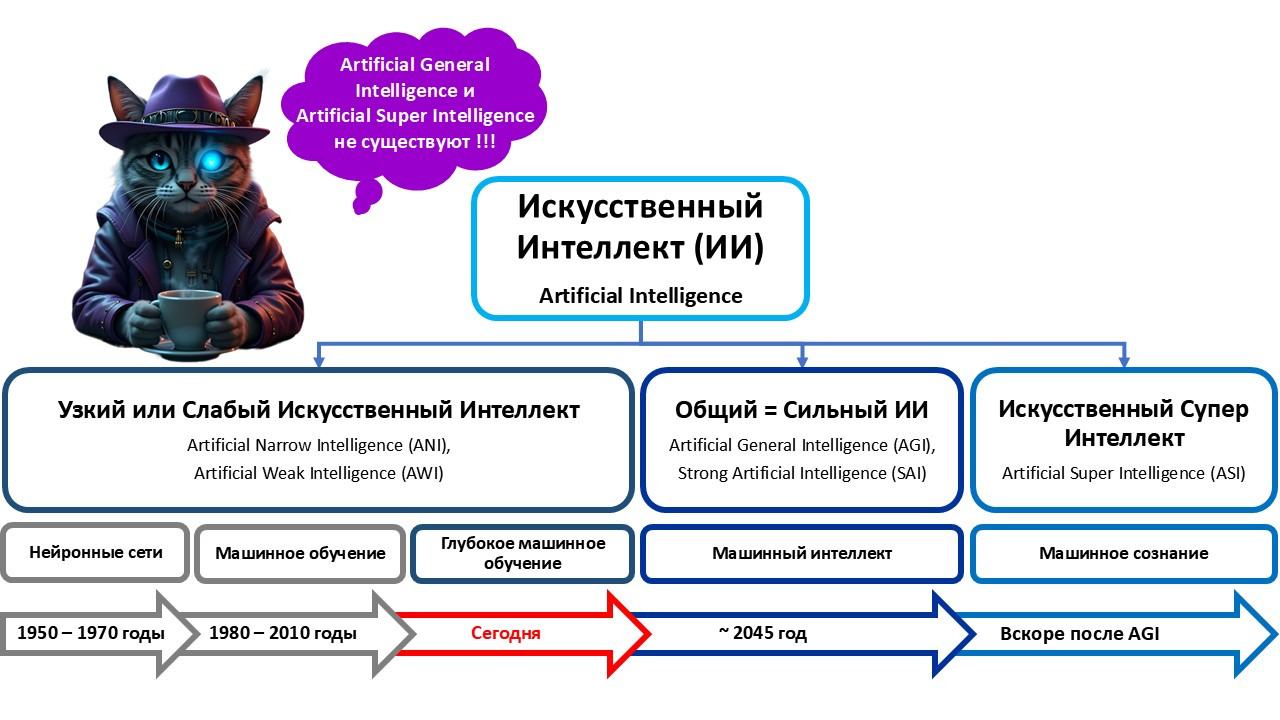
На сегодняшний день систем искусственного сверхинтеллекта, так же, как и систем сильного или общего искусственного интеллекта, не существует. Многие ученые считают, что до создания суперинтеллекта пройдет очень много времени, но большинство из них все же сходятся во мнении, что это рано или поздно произойдет.
На мой взгляд, случится это тогда, когда люди смогут создать такие суперкомпьютеры и системы хранения информации, которые будут способны производить вычисления и хранить данные, как наш человеческий мозг.
Знаете ли вы, что наш с вами мозг и нервная система — это суперкомпьютер со своей системой хранения данных и интерфейсов взаимодействия с внешним миром?
За обработку информации в нашем мозге отвечают порядка 86–100 млрд нейронов (нейронных клеток), которые меняют свое состояние до 50 раз в секунду. Число возможных состояний нашего мозга = 101000000 (количество возможных комбинаций возбуждения или торможения нейронов), тогда как количество атомов во Вселенной = 1080.
Кроме того, на сегодняшний день никто не может дать ответ на вопрос, сколько экзабайт (1018) или йоттабайт (1024) данных и в какой форме хранится в нашем мозге.
Исходя из этих скромных данных, мы можем с вами сделать вывод о том, что появление искусственного сверхинтеллекта возможно лишь тогда, когда человечество создаст квантовые носители информации и квантовый суперкомпьютер, сопоставимый по своим вычислительным мощностям с нашим мозгом.
Тем не менее ученые из разных стран полны энтузиазма и ведут работы по созданию общего, а затем уже и суперинтеллекта. Приведу некоторые из этих направлений, которые, на мой взгляд, будут вам интересны:
— Эмуляция работы человеческого мозга. Задача заключается в создании полной цифровой копии человеческого мозга. Для этого осуществляется сканирование всей структуры мозга человека для создания точной цифровой карты его нейронных связей.
— Мозговые импланты. Ученые работают над тем, чтобы создать такие устройства, которые можно будет встраивать в человеческий мозг для улучшения его работы. Предполагается, что это позволит достичь уровня сверхразума за счет симбиоза человека и машины.
— Создание эволюционных распределенных систем искусственного интеллекта. Основная идея этого подхода заключается в том, чтобы системы искусственного интеллекта смогли самостоятельно развиваться и эволюционировать с тем, чтобы через несколько этапов превратиться в суперинтеллект.
— Нейроморфные вычисления. Ученые работают над тем, чтобы создать нейроморфные компьютеры, работа которых основана на работе нейронных и синаптических структур человеческого мозга. Считается, что такие суперкомпьютеры в десятки раз производительнее современных суперкомпьютеров, работающих на графических ускорителях.
По моему мнению, вам будет интересна точка зрения, которая имеет отношение к теме искусственного сверхинтеллекта, выдающегося физика-теоретика Стивена Хокинга, которая, возможно, откроет вам новую перспективу нашего с вами будущего: «Боюсь, искусственный интеллект может полностью заменить людей. Если сейчас люди разрабатывают компьютерные вирусы, то в будущем кто-то сможет создать искусственный интеллект, который будет способен улучшать и воспроизводить самого себя. Это станет новой формой жизни, которая превзойдет человека».
Объяснимый искусственный интеллект (Explainable Artificial Intelligence, XAI) — набор правил и методов, позволяющих пользователям системы искусственного интеллекта понять, почему алгоритмы машинного обучения этой системы пришли именно к тем или иным результатам работы и/или выводам. Объяснимый искусственный интеллект обеспечивает прозрачность работы используемой системы ИИ для ее пользователей, по своей сути противопоставляя себя принципу «черного ящика» в машинном обучении.
Вопросы объяснимости получаемых результатов работы системы искусственного интеллекта, на самом деле, интересуют не только нас с вами как пользователей таких систем, но и инженеров-программистов, их создающих.
Когда разработчики переходят от программирования и экспериментов по решению простейших задач автоматизации к разработке серьезных программных систем, например систем поддержки принятия решений, они должны не только сами понимать, на основании чего получаются те или иные результаты работы, но и быть готовыми объяснить их происхождение пользователям системы искусственного интеллекта, которую они разрабатывают. Это необходимо делать еще и потому, что каждый разработчик несет персональную ответственность за создаваемые им алгоритмы, модели, программы, системы и другие приложения и сервисы, которые впоследствии будут использованы людьми. Неверно принятое решение на «необъяснимых» результатах работы системы искусственного интеллекта может привести к катастрофическим последствиям как для отдельно взятого человека, так и для отдельно взятой компании, города или даже целой страны.
Очень часто бывает так, что программист, обучающий модель, не является экспертом в той или иной предметной области, и это, на самом деле, большая проблема. Например, программист не является врачом, что, конечно, очевидно. Как вам известно, многие врачи обладают огромным запасом знаний, опыта и интуиции, которые с первого взгляда могут сказать, что нельзя доверять тем или иным данным, полученным от использования какой-то конкретной модели, применяемой в системе поддержки принятия решений. Специалист сразу отметит, что модель делает неразумный прогноз. Несомненно, программисты и врачи должны работать в тесной кооперации, но очень часто бывает так, что программист принимает решение о тех или иных результатах работы самостоятельно, что может повлечь за собой наличие скрытой ошибки при расчетах и точности получаемых данных. Именно в таких случаях при разработке систем искусственного интеллекта инженеры-программисты должны уделять большое внимание вопросам объяснимости.
На рисунке ниже показан современный подход к созданию объяснимого искусственного интеллекта.
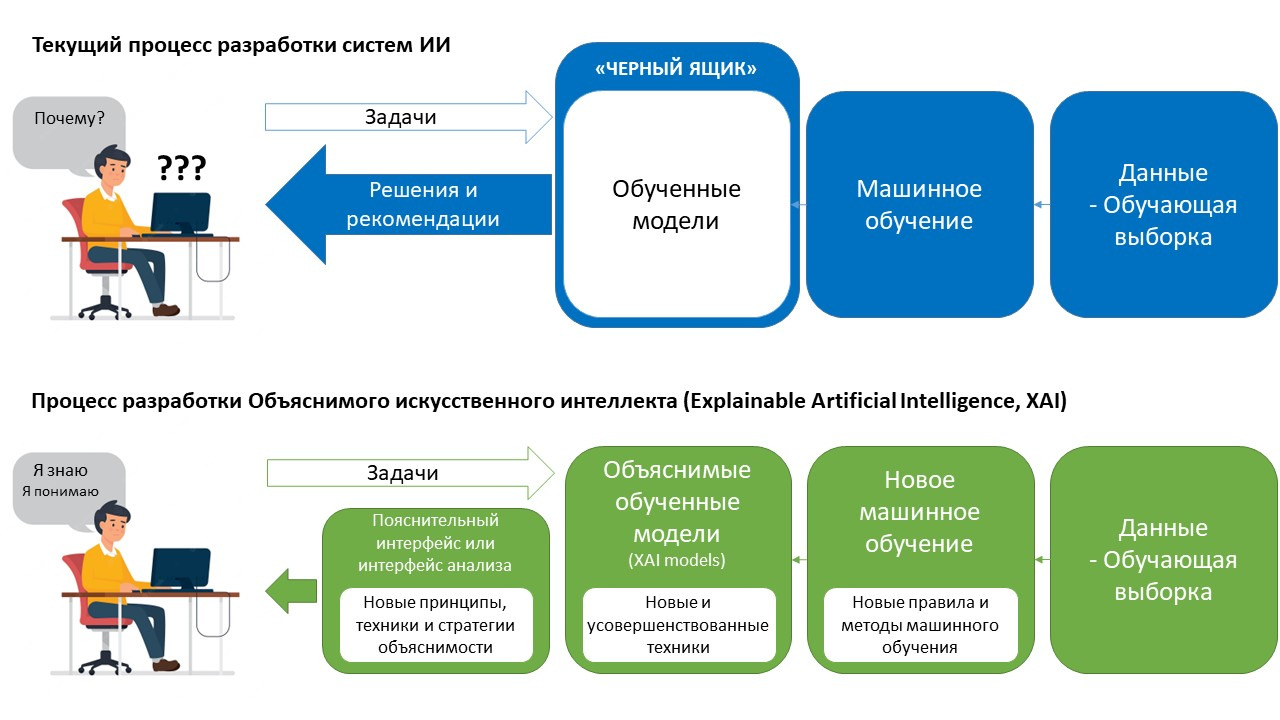
Как мы с вами видим, на сегодняшний день необходимо создание дополнительных инструментов понимания и объяснимости работы системы искусственного интеллекта, которые бы были полезными при принятии решений о том, заслуживают полученные с ее помощью данные доверия или нет,.
Например, инженеры-программисты для объяснения предсказаний базовых моделей машинного обучения и оценки их полезности в различных задачах классификации и регрессии используют библиотеку «Lime». На сегодняшний день библиотека работает с анализом текстовых и табличных классификаторов, а также работает с классификаторами изображений. Lime может объяснить любой классификатор «черного ящика» с двумя или более классами.
Как мы с вами видим, необходимость в реализации объяснимого искусственного интеллекта как для разработчика, так и для нас с вами как пользователей систем искусственного интеллекта становится не только очевидной, но и вполне важной и ответственной задачей.
Еще одним немаловажным свойством системы искусственного интеллекта, выступающим наравне с «объяснимостью», является ее «прозрачность». В английском языке слово «прозрачность» (англ. «transparency») является синонимом слову «безошибочность» (англ. «unmistakableness»).
Прозрачность работы систем искусственного интеллекта обеспечивается предоставлением полноценной открытой информации для пользователей систем искусственного интеллекта (то есть для нас с вами) о том, какие продукты или услуги предоставляются напрямую или с помощью систем искусственного интеллекта. А также какие управленческие решения принимаются теми или иными физическими лицами, компаниями или организациями на основе данных, полученных и предоставленных системами искусственного интеллекта. Эта информация должна указывать на то, что принимаемые решения не нарушают права человека (пользователей систем искусственного интеллекта) и не подвергают его какой-либо опасности. Высокий уровень прозрачности обеспечит возможность контроля со стороны общества, что, в свою очередь, может способствовать снижению уровня коррупции, дискриминации или рисков возникновения того или иного вида ущерба.
Таким образом, обеспечение объяснимости и прозрачности работы систем искусственного интеллекта является существенным условием не только при их проектировании и разработке, но и при их эксплуатации с целью обеспечения уважения к частной жизни граждан и защиты прав и свобод человека в течение всего жизненного цикла создаваемых систем ИИ,,.
Термины «прозрачность» и «объяснимость» являются неотъемлемыми критериями оценки системы «доверенного искусственного интеллекта», с определением которой мы познакомимся с вами в следующей главе.
Доверенный искусственный интеллект (Trusted Artificial Intelligence) — это прикладная система искусственного интеллекта, обеспечивающая выполнение возложенных на нее задач с учетом ряда дополнительных требований, обеспечивающих доверие к результатам работы системы, включающих в себя:
— достоверность и интерпретируемость выводов и предлагаемых решений, полученных с помощью системы и проверенных на верифицированных тестовых примерах;
— безопасность как с точки зрения невозможности причинения вреда пользователям системы на протяжении всего жизненного цикла системы, так и с точки зрения защиты от взлома, несанкционированного доступа и других негативных внешних воздействий;
— приватность и верифицируемость данных, с которыми работают алгоритмы искусственного интеллекта, включая разграничение доступа и другие связанные с этим вопросы;
— внедрение этических аспектов применения искусственного интеллекта.
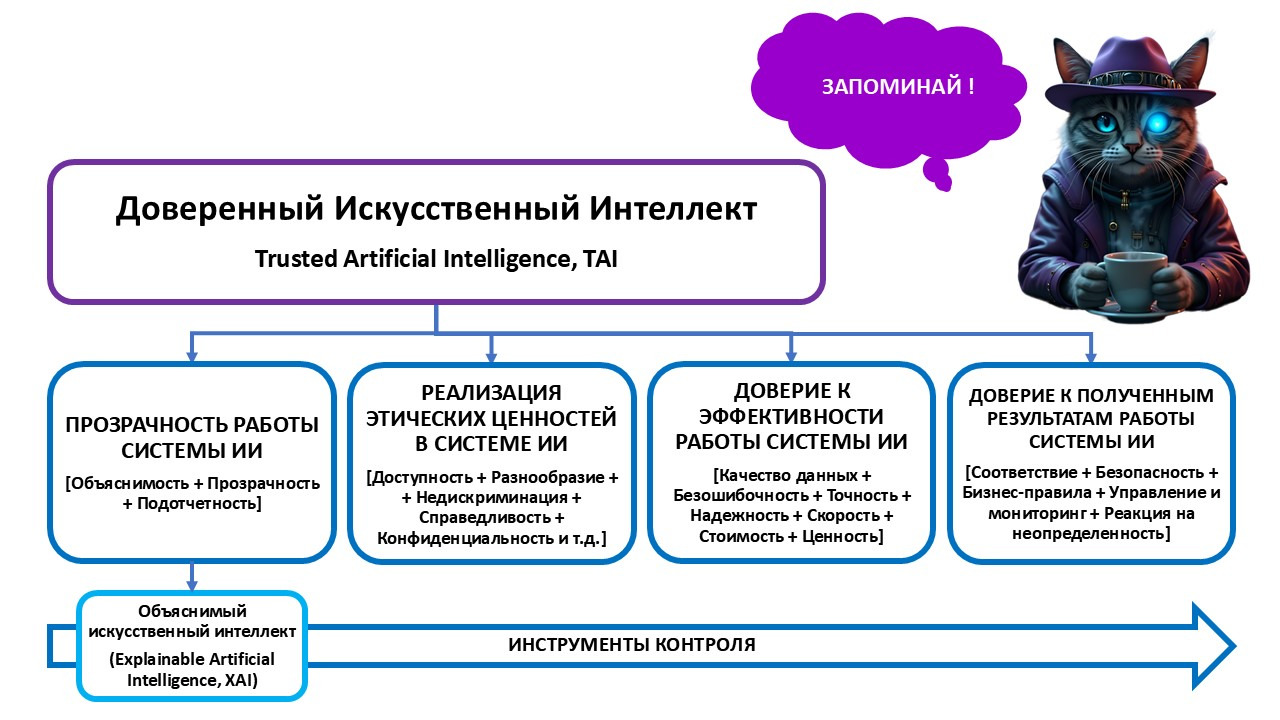
Надежный искусственный интеллект основан на идее о том, что доверие к его работе создает основу общества, экономики и устойчивого развития. Люди, организации и общества могут реализовать весь потенциал систем искусственного интеллекта только в том случае, если доверие может быть установлено при его разработке, внедрении, поддержке и использовании,.
Этичный искусственный интеллект (Ethical Artificial Intelligence) — это система доверенного искусственного интеллекта, придерживающаяся в своей работе строго определенных этических принципов в отношении фундаментальных человеческих ценностных установок, включая такие, как уважение, защита и поощрение прав человека; благополучие окружающей среды и экосистем; обеспечение разнообразия и инклюзивности (процесса включения людей с физической и ментальной инвалидностью в полноценную общественную жизнь); жизнь в мирных, справедливых и взаимосвязанных обществах.
Генеративный искусственный интеллект — это самый перспективный метод глубокого машинного обучения, при котором нейросеть изучает массив больших данных, например фотографии, видео или текст, на определенную тему, после чего, используя полученную информацию, создает свой собственный уникальный контент.
Помимо уникального контента, генеративный искусственный интеллект может создавать уникальные технологические, производственные и бизнес-процессы, которые могут помочь улучшить различные операции.
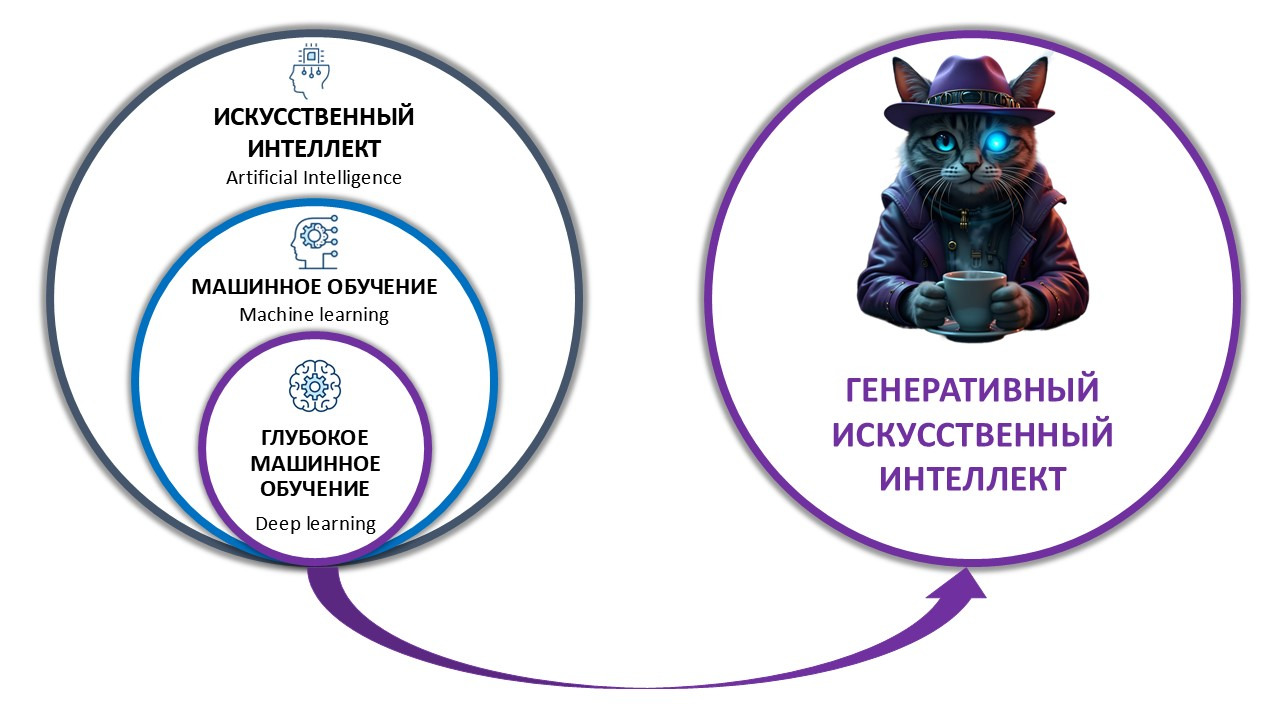
Например, улучшить процессы поставки товаров и услуг, процессы производства продукции, управления хранением готовой продукции и ее продажами.
Генеративный искусственный интеллект может быть использован для создания новых лекарств в медицине и новых материалов в химии и промышленности. Если мы с вами рассматриваем генерацию изображений, то его применение может быть не только в компьютерных играх, но и в производстве новых продуктов, рекламе, маркетинге, электронной коммерции и обучении.
Также генеративный искусственный интеллект применяют для создания музыки, голоса, литературных произведений, извлечения ключевой информации, поиска решений, видео, дизайна и много другого.
Многие компании и предприятия рассматривают генеративный искусственный интеллект как ключевой драйвер для последующих этапов цифровой трансформации и автоматизации.
Как отметил руководитель Bloomberg Intelligence Мандип Сингх: «В течение следующих десяти лет мир ожидает взрывной рост в секторе генеративного ИИ, который обещает фундаментально изменить способ работы технологического сектора».
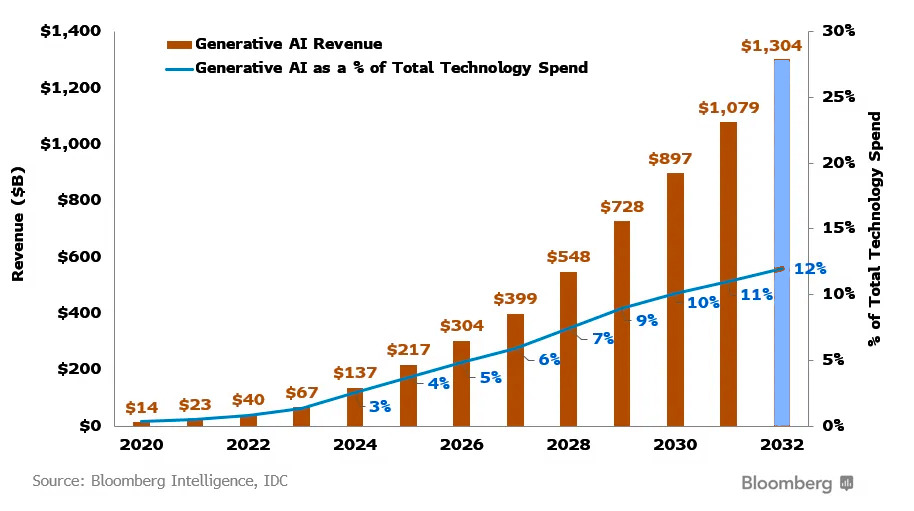
Согласно отчету Bloomberg Intelligence, облачное подразделение Amazon.com Inc., Google Alphabet Inc., Nvidia Corp. и Microsoft Corp. (владеющая OpenAI) окажутся в числе лидеров рынка искусственного интеллекта к 2032 году.
По прогнозам Bloomberg Intelligence, крупнейшим фактором роста доходов от генеративного ИИ станет спрос на инфраструктуру, необходимую для обучения моделей ИИ, который к 2032 году составит около 247 миллиардов долларов. Ожидается, что к 2032 году годовой доход от бизнеса цифровой рекламы с использованием ИИ достигнет 192 миллиардов долларов, а доход от серверов ИИ может достичь 134 миллиардов долларов, говорится в отчете. В итоге рынок генеративного искусственного интеллекта к 2032 году достигнет 1,3 триллиона долларов.
На сегодняшний день, по мнению ученых и специалистов, возможности систем генеративного искусственного интеллекта практически не имеют границ. Они способны с большой скоростью создавать новый уникальный контент, идеи, разговоры, истории, сценарии, художественные произведения в стиле знаменитых писателей, произведения изобразительного искусства в стиле знаменитых художников, видео и музыку в стиле знаменитых композиторов разных эпох.
Работа генеративного искусственного интеллекта основана на базовых моделях глубокого машинного обучения, предварительно обученных на больших данных. Ярким примером базовой модели является модель GPT (не путайте с ChatGPT, который является web-приложением). Она представляет собой большую языковую модель (или, как еще говорят, семейством моделей нейронных сетей), специально разработанную для решения языковых задач, таких как обобщение, генерация текста в реальном времени, классификация, открытые вопросы и ответы, а также извлечение информации. Появление моделей GPT стало переломным моментом в широком распространении машинного обучения, поскольку теперь эту технологию можно использовать для автоматизации и улучшения широкого спектра задач, начиная с переводов текстов на различные языки и заканчивая написанием постов в блогах, созданием веб-сайтов, визуальных эффектов, анимации, написанием программного кода, анализом данных и созданием интеллектуальных голосовых помощников. Ценность подобных моделей заключается в скорости их работы и направлениях, в которых они могут быть применены,.
Модель глубокого машинного обучения представляет собой сложную алгоритмическую структуру, обученную на больших наборах данных, чтобы впоследствии автономно выполнять определенные задачи, такие как генерация изображений, текста, переводы на другие языки или принятие решений. Эти модели обучаются на разнородных или однородных данных, чтобы имитировать когнитивные способности человека, что позволяет им понимать наши запросы и генерировать новый уникальный контент. Как правило, модель представляет собой компьютерный файл большого размера. Качество работы модели во многом зависит от качества и объема данных, на которых она была обучена.
Наиболее популярные модели, которые позволяют создавать уникальные изображения из текстовых описаний (запросов), — это Stable Diffusion, Midjourney и DALL-E, а с 2024 года — FLUX.1 и FLUX1.1.
Существуют также языковые модели, которые могут генерировать текст, переводить тексты на иностранные языки, писать различные виды креативного контента и отвечать на вопросы пользователей. Наиболее известные среди них — это Generative Pre-trained Transformer (GPT), GPT4-Omni, Llama, Claude, Cohere Command (Command R и Command R+), Mistral, Gemini и другие.
Также есть модели, которые способны генерировать программный код на различных языках программирования (например, C#, Java, Python, JavaScript, SQL, Go, PHP и Shell). Наиболее известные — это CodeWhisperer, CodeLlama и Codex.
К системам генеративного искусственного интеллекта относится система Stable Diffusion WebUI Forge, которую мы изучим в этой книге. А в качестве базовых моделей для генерации изображений мы будем использовать различные версии модели FLUX.1, созданные Black Forest Lab.
Возможно, в ближайшем будущем многое из того, что вы будете создавать или использовать в своей учебе и работе, будет создано с помощью различных систем генеративного искусственного интеллекта.
Самые популярные системы генерации изображений
На сегодняшний день существует достаточно большое количество различных платных и бесплатных программ, которые на базе технологий генеративного искусственного интеллекта создают невероятно красивые изображения. Некоторые из этих программ можно загрузить и установить на свой домашний или рабочий компьютер и работать с ними автономно без подключения к сети. Тем не менее большинство из них находятся в сети интернет. Множество сайтов предоставляют различные on-line-сервисы по созданию изображений с применением различных моделей искусственного интеллекта. Эти сайты в основном используют модели для генерации изображений Stable Diffusion, Midjourney, Kandinsky и многие другие.
На мой взгляд, наибольшей популярностью пользуются следующие программы и сервисы:
— Midjourney — очень популярная система генеративного искусственного интеллекта, созданная одноименной компанией Midjourney. Искусственный интеллект Midjourney — это web-сервис в сети интернет, который позволяет создавать очень красивые изображения, при этом не задействуя вычислительные ресурсы вашего компьютера. Для ее использования у вас должна быть установлена программа Discord — удобный мессенджер для групповой работы, который часто используют игроки по всему миру. Основной недостаток программы заключается в том, что не так давно Midjourney стала полностью платной.
— Stablecog — это очень простой в использовании, но в то же время очень удобный web-сервис. К сожалению, он платный. Тем не менее это мой любимый сервис. В день можно создать двадцать бесплатных изображений. Если вы долго не работали с сервисом после регистрации, ваши баллы за пропущенные дни суммируются.
Не так давно в Stablecog появилась модель FLUX.1.
— Leonardo.Ai — это красочный web-сервис в сети интернет, предоставляющий доступ к одноименной нейросети Leonardo.Ai. С ее помощью вы можете создавать изображения из текста и других изображений. К достоинствам Leonardo.Ai можно отнести удобный в использовании интерфейс работы. К недостаткам — это ограничение на число создаваемых изображений в день. Изображения создаются очень быстро и качественно, но пока вы научитесь делать что-то качественное, пройдет достаточно много времени. Если вы захотите потратить больше времени на работу с этой программой, готовьтесь заплатить за дополнительные функции. Очень часто Leonardo.Ai сравнивают с Midjourney, но кто из них лучше, это решать только вам.
— Easy Diffusion — полностью бесплатная система искусственного интеллекта, которая объединила в себе возможности использования Midjourney и Stable Diffusion. Easy Diffusion предлагает вам удобный и простой web-интерфейс, который позволяет не только создавать очень красивые изображения, но и подключать к ее работе различные дополнительные модули и модели. По умолчанию в программе уже предустановлена нам известная модель Stable Diffusion.
К еще одному достоинству программы можно отнести то, что она очень просто устанавливается на компьютер или ноутбук и работает с не очень мощными видеокартами. К недостатку программы можно отнести только затрачиваемое вами время на создание изображений. Например, если изображение в Dreamstudio.ai создается за 20 секунд, то в Easy Diffusion на создание может уходить до 120 секунд.
Еще раз обращу ваше внимание на то, что Easy Diffusion — это простая к установке сборка программных пакетов (или, другими словами, дистрибутив) системы генеративного искусственного интеллекта Stable Diffusion для различных операционных систем.
К сожалению, вы можете скачать дополнительно с сайта www.civitai.com (где есть очень много полезных моделей) новую модель FLUX.1 (хотя много вариантов ее реализации там уже выложили). Я проверил, и на момент написания этой книги там нет ни одной работающей с Easy Diffusion.
Подробно об Easy Diffusion я рассказываю в своей книге «Невероятный искусственный интеллект Easy Diffusion 3.0».
— Dreamstudio.ai — это web-сервис, созданный компанией Stability AI, которая разработала одну из самых известных нейросетевых моделей под названием Stable Diffusion. Web-сервис очень удобный и позволяет создавать любые изображения очень быстро. Это происходит потому, что сервис Dreamstudio.ai использует очень мощные сервера для генерации изображений. Другими словами, ваш компьютер не задействуется в процессе создания изображений, что является существенным достоинством программы. В то же время недостатком использования Dreamstudio.ai является ограничение на число создаваемых картинок.
— Stable Diffusion Web UI — это программа с удобным web-интерфейсом, которую вы можете установить непосредственно на свой компьютер. К ее достоинствам можно отнести то, что это полностью бесплатный вариант использования модели Stable Diffusion.
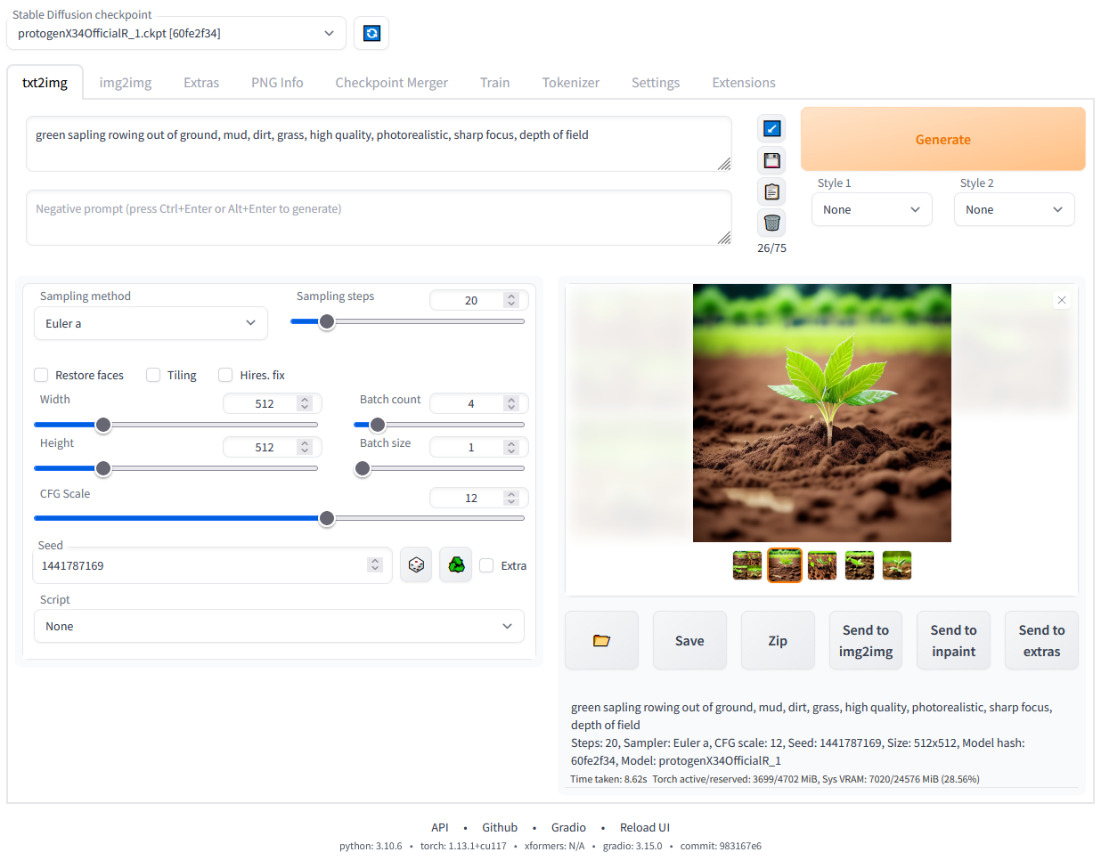
В программе можно выбрать гибкие настройки для улучшения качества изображения и его преобразования в новую версию или создания на ее основе другого изображения. К недостаткам можно отнести некоторые трудности, связанные с установкой и необходимостью наличия у вас дополнительных знаний о программах, необходимых для ее работы (например таких, как Python и Git). Stable Diffusion можно рекомендовать всем тем пользователям, кто уже получил большой опыт работы с Easy Diffusion,,.
— Stable Diffusion WebUI Forge — это новая разработка, основанная на базе Stable Diffusion WebUI и поддерживающая работу новой модели FLUX, которую можно установить на свой компьютер и работать без привязки к сети интернет бесплатно.
В этой книге мы подробно рассмотрим подробно работу программы Stable Diffusion WebUI Forge и модели FLUX.1.
Часть 2. Установка и удаление Stable Diffusion WebUI Forge
Шаг 1. Установка Stable Diffusion WebUI Forge
Для того чтобы определиться с выбором сборки (или дистрибутива), нам необходимо с вами получить нужную информацию от нашей операционной системы, чтобы узнать версию CUDA (Compute Unified Device Architecture).
CUDA — это технология, работающая на базе программно-аппаратной архитектуры, которая позволяет повысить производительность параллельных вычислений. Параллельные вычисления — это вычисления, при которых процесс разработки программного обеспечения делится на потоки. Потоки обрабатываются параллельно и взаимодействуют между собой в процессе обработки. Технология CUDA поддерживается процессорами видеокарт NVIDIA, которые используют системы генеративного искусственного интеллекта для создания различного контента.
Для определения версии CUDA в строке поиска наберем и выполним команду cmd, как показано на рисунке ниже:
После того как вы выполните команду cmd, нажав кнопку Enter на клавиатуре, перед вами откроется консоль для ввода пользователем текстовых команд.
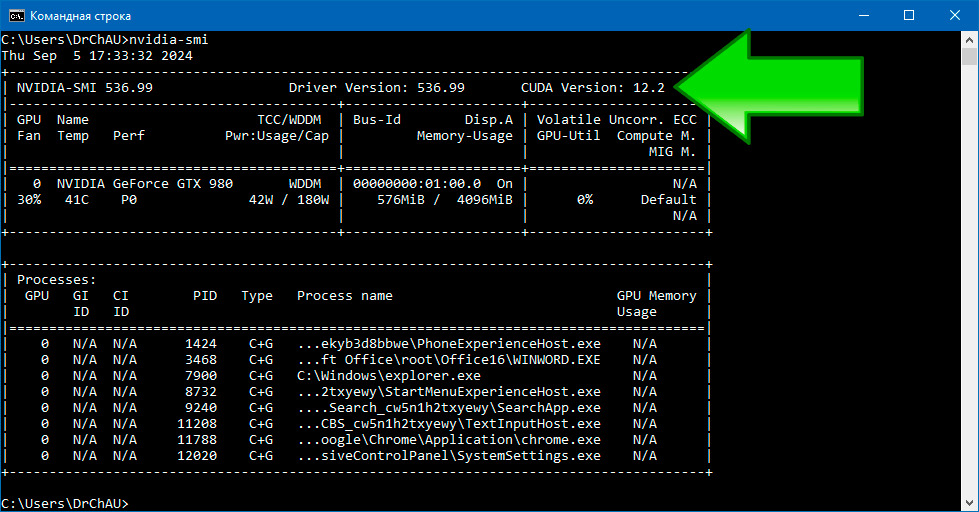
В ней вам нужно ввести команду nvidia-smi и нажать Enter.
В результате вы увидите следующую таблицу, где справа сверху будет написана версия CUDA:
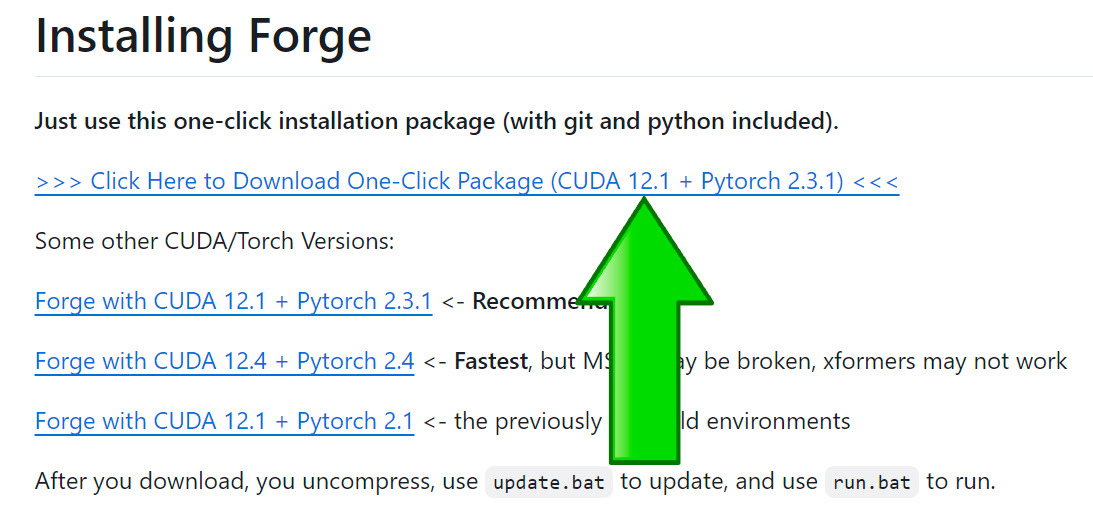
После чего вы открываете свой интернет-браузер и переходите на страницу: https://github.com/lllyasviel/stable-diffusion-webui-forge?tab=readme-ov-file, где ближе к середине страницы находите ссылку на файл дистрибутива.
В зависимости от версии CUDA выбираете ссылку для скачивания, как показано на рисунках ниже.
Для вашего удобства я ее перевел:
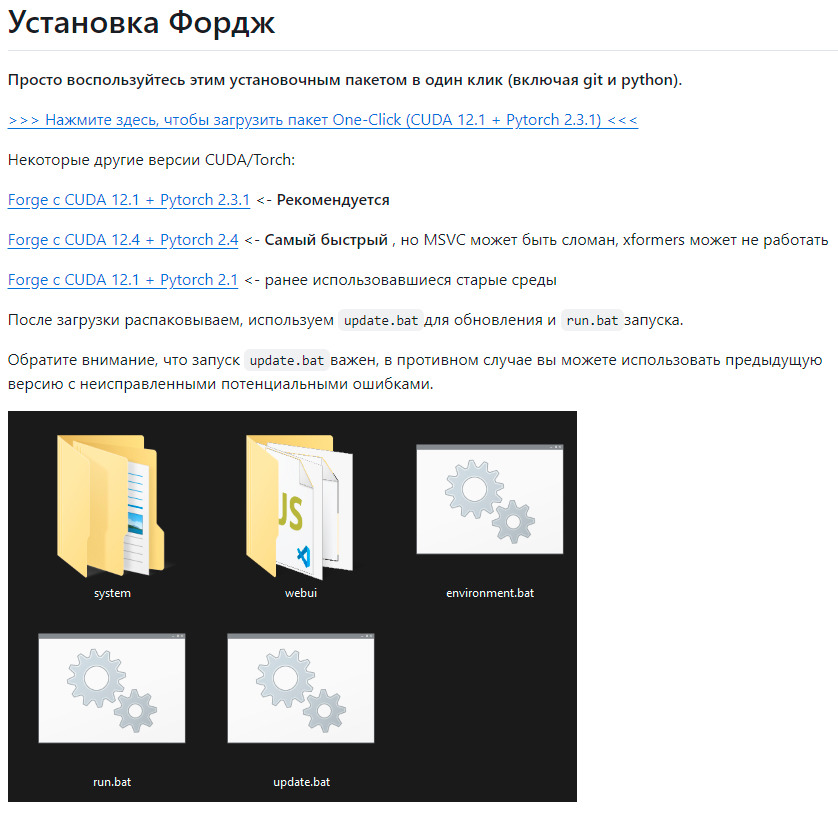
У меня версия CUDA 12.2, поэтому я выбираю первую ссылку для скачивания.
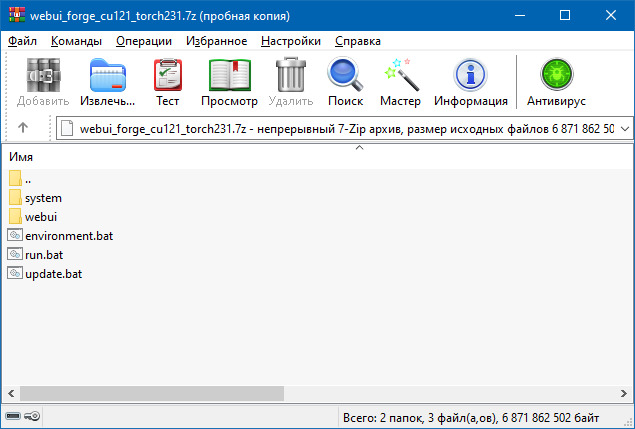
После чего на ваш компьютер загрузится архивный файл webui_forge_cu121_torch231.7z.
Для его распаковки вам понадобится архиватор 7z, который можно скачать бесплатно, или Zip-архиватор.
Внутри архива вы увидите следующие папки:
Создайте на любом диске, где у вас есть достаточно места, папку с названием «Stable Diffusion WebUI Forge» и распакуйте содержимое архивного файла в эту папку (например, у меня файлы находятся по следующему пути: D:\Stable Diffusion WebUI Forge).
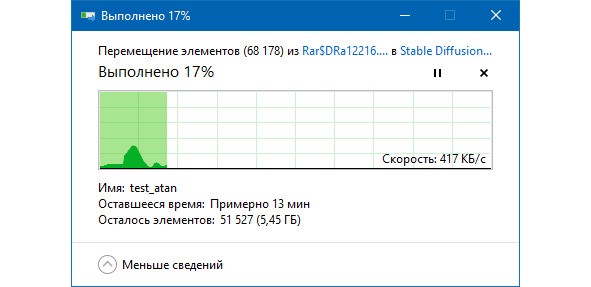
Нужно отметить, что для программы Stable Diffusion WebUI Forge нужно 6,5 Гбайт дискового пространства, а для моделей FLUX.1 — еще 50 Гбайт.
Но это еще не предел!
Постарайтесь найти на диске не менее 200 Гбайт свободного пространства, потому что в дальнейшем мы будем устанавливать дополнительные модули и модели для расширения функциональных возможностей системы.
После распаковки файлов в папку «Stable Diffusion WebUI Forge» программа Stable Diffusion WebUI Forge полностью установлена на ваш компьютер.
Но пока что не спешите ее запускать. Нам еще нужно сделать два важных действия, о которых речь пойдет дальше.
Шаг 2. Установка модели FLUX.1
После установки системы Stable Diffusion WebUI Forge, которая обеспечит нам удобный интерфейс и работу с большим числом различных функций и параметров, нам теперь необходимо скачать файл нужной нам версии модели FLUX.1, которая бы быстро и качественно работала на нашем компьютере.
Напомню вам, что есть три основные версии модели, созданные разработчиками Black Forest Lab:
— FLUX.1 [pro] — самая мощная версия реализация коммерческой модели, доступная к использованию только через API у партнеров компании Black Forest Lab или в индивидуальном порядке.
— FLUX.1 [dev] — немного облегченный вариант первой модели не для коммерческого использования. Варианты реализации модели можно найти на сайте huggingface.co. Она может быть использована на локальных компьютерах.
Сайт с моделью от разработчика: https://huggingface.co/black-forest-labs/FLUX.1-dev.
— FLUX.1 [schnell] — самая быстрая реализация модели с открытым исходным кодом, которая так и называется: «быстрая, шнель / нем. schnell». Она предназначена для использования на локальных компьютерах. Исходный код можно найти на сайте GitHub. Варианты реализации модели можно найти сайте huggingface.co.
Сайт с моделью от разработчика: https://huggingface.co/black-forest-labs/FLUX.1-schnell.
Несомненно, нужно начинать свою работу с установки и тестирования той из них, которая будет соответствовать производительности вашего компьютера и будет создавать изображения максимального качества для вас.
На самом деле, версий модели FLUX от сторонних разработчиков уже достаточно много.
Но для того чтобы нам быстро перейти к от теории к практике, мы возьмем за основу уже подготовленные модели, которые называются «nf4-модели».
Nf4-модели — это полноценные FLUX-модели, которые не требуют установки дополнительных компонент для Stable Diffusion WebUI Forge и помогают нам создавать очень красивые изображения. Они отличаются от стандартных моделей FLUX используемым в них методом nf4-квантования (о чем скажу чуть позже), меньшим размером исходного файла, что хорошо для менее производительных видеокарт.
Существует несколько версий уже подготовленных файлов моделей FLUX.1 [dev] и FLUX.1 [schnell] от разных разработчиков. Рассмотрим некоторые из них, которые наиболее стабильно работают (от разработчиков silveroxides и lllyasviel).
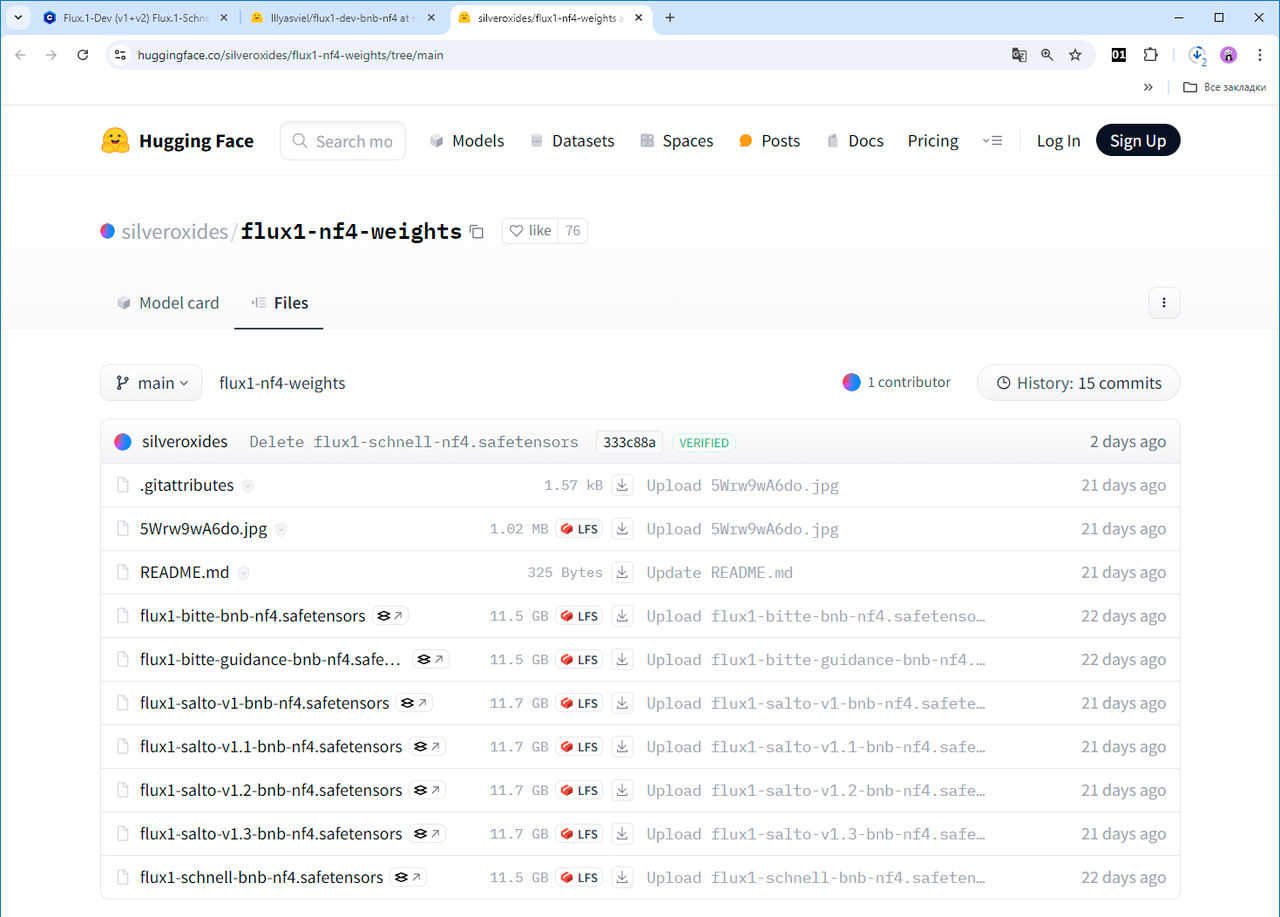
Готовый файл самой быстрой модели FLUX.1 [schnell] для не очень мощных компьютеров с видеокартами предыдущих поколений (например, как у меня NVIDIA GTX 980 с 4 Гбайтами видеопамяти) называется flux1-schnell-bnb-nf4.safetensors. Я протестировал работу этого файла, и он показал себя очень хорошо при создании различных изображений.
Скачать файл можно по следующей ссылке: https://huggingface.co/silveroxides/flux1-nf4-weights/tree/main.
Если у вас видеокарта серии NVIDIA GTX 10XX/20XX или более новая, то вам необходимо скачать следующий файл модели flux1-dev-bnb-nf4-v2.safetensors по следующей ссылке: https://huggingface.co/lllyasviel/flux1-dev-bnb-nf4/tree/main.
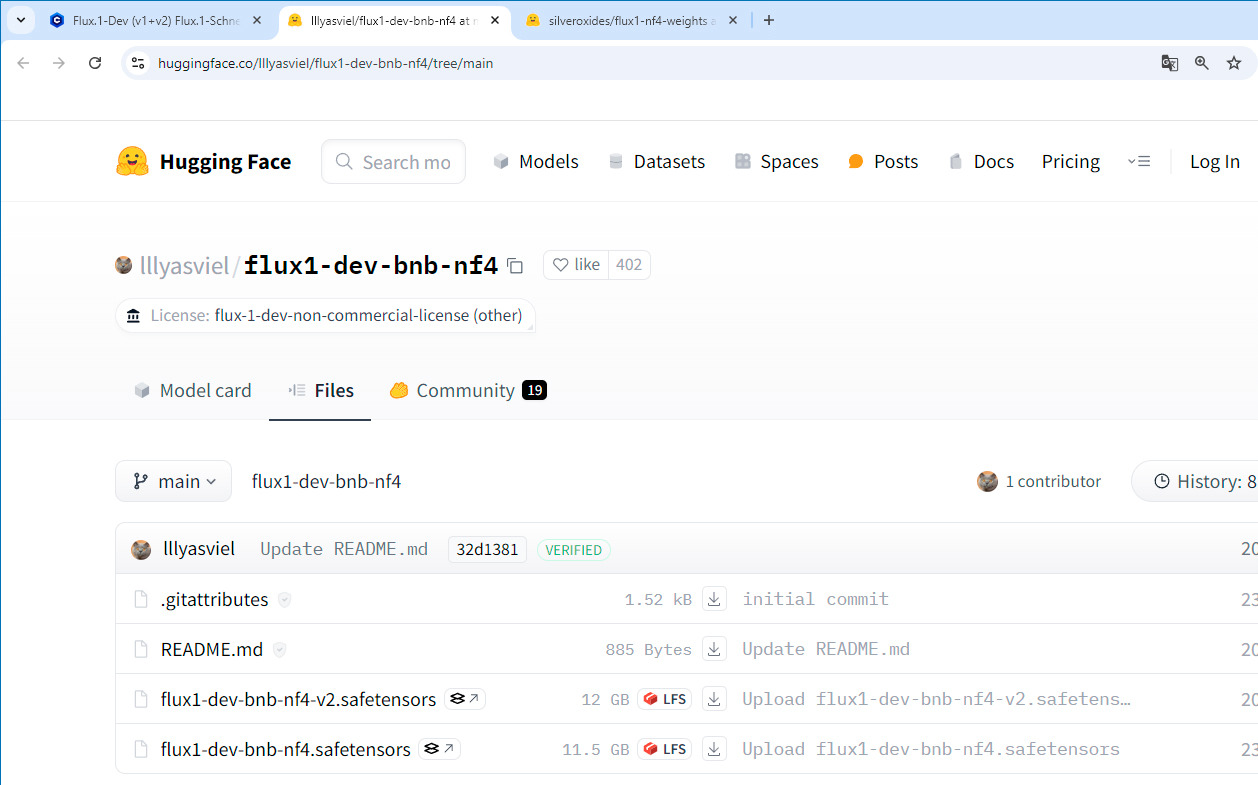
По заявлению разработчика, модель второй версии flux1-dev-bnb-nf4-v2.safetensors работает быстрее, но она чуть больше по размеру файла.
Если у вас видеокарта серии NVIDIA RTX 30xx/40xx, то вы можете скачать файл модели flux1-dev-fp8.safetensors по следующей ссылке:
https://huggingface.co/lllyasviel/flux1_dev/blob/main/flux1-dev-fp8.safetensors.
Если вы обратите внимание, файл этой реализации модели значительно больше остальных по своему размеру, да и как показывает практика flux1-dev-bnb-nf4-v2.safetensors — это лучший выбор для учебы и творчества.
Таким образом, вы загрузили для себя один (или несколько) из необходимых фалов модели FLUX.1.
Модель FLUX.1 [schnell]:
— файл flux1-schnell-bnb-nf4.safetensors;
Модель FLUX.1 [dev]:
— файл flux1-dev-bnb-nf4-v2.safetensors;
— файл flux1-dev-bnb-nf4.safetensors);
— файл flux1-dev-fp8.safetensors.
Теперь загруженный файл (или файлы) модели нам нужно переместить в папку моделей «Stable-diffusion».
Например, эта папка у меня находится по следующему пути: D:\Stable Diffusion WebUI Forge\webui\models\Stable-diffusion.
Открываем папку и копируем туда файл или все файлы моделей.
Теперь мы с вами почти готовы к первому рабочему запуску программы Stable Diffusion WebUI Forge.
Наверное, вы обратили свое внимание на то, что в именах файлов написаны такие сокращения: «fp8» и «nf4». Оба сокращения имеют прямое отношение к методу обработки информации, который называется «квантование» (англ. quantization).
Квантование в информатике — это разбиение диапазона значений непрерывной или дискретной величины на конечное число интервалов. Существует также векторное квантование — разбиение пространства возможных значений векторной величины на конечное число областей.
Квантование для сетей глубокого обучения является важным шагом для ускорения вывода данных, а также для сокращения потребления ресурсов памяти и потребления электроэнергии вашей видеокартой. Масштабированное 8-битное целочисленное квантование сохраняет точность модели, одновременно уменьшая ее размер. Это позволяет развертывать модель на устройствах с меньшим объемом оперативной памяти, оставляя больше места для работы других алгоритмов и логики управления,.
Говоря простым языком, модель «nf4» должна работать быстрее «fp8», но при условии ее аппаратной поддержки вашей видеокартой. Как я понимаю, это напрямую зависит от версии драйвера CUDA (Compute Unified Device Architecture), которую поддерживает ваша видеокарта, и объема оперативной памяти видеокарты.
Забегу немного вперед и скажу сразу, что мне удалось запустить на своем компьютере с видеокартой NVIDIA GTX 980 с 4 Гбайтами видеопамяти следующие модели, которые при генерации изображения размером 512 на 512 показали следующие результаты:
— flux1-schnell-bnb-nf4.safetensors — на создание изображения уходит в среднем 3 мин.
— flux1-dev-bnb-nf4.safetensors — на создание изображения уходит в среднем 6 мин.
— flux1-dev-bnb-nf4-v2.safetensors — на создание изображения уходит в среднем от 3 до 6 мин.
— flux1-dev-fp8.safetensors — на создание изображения уходит в среднем от 3 до 7 мин.
Также я оттестировал работу всех моделей на видеокарте NVIDIA GTX 2060 с 12 Гбайтами видеопамяти и заметил интересную особенность, которая заключается в том, что первое изображение на этой карте создается приблизительно за такое же время, как и на видеокарте NVIDIA GTX 980 с 4 Гбайтами видеопамяти (в среднем три минуты). Но далее проявляется существенное отличие этих карт, которое заключается в том, что NVIDIA GTX 2060 все последующие изображения создает в несколько раз быстрее.
В связи с тем что серии видеокарт NVIDIA RTX 30xx/40xx стоят достаточно дорого, видеокарта NVIDIA GTX 2060 с 12 Гбайтами видеопамяти является лучшим выбором по цене и качеству как для учебы, так и для игр.
Подробнее мы остановимся на этом моменте в следующей главе «Первый запуск и тест вариантов моделей FLUX».
Шаг 3. Дополнительная настройка компьютера
Перед тем как запускать программу Stable Diffusion WebUI Forge, по рекомендации разработчика нам необходимо подготовить свой компьютер к тяжелой работе и сделать некоторые настройки, а именно изменить размер файла подкачки системы.
Для этого наводим курсор мышки на иконку «Мой компьютер», нажимаем правой кнопкой мыши и выбираем «Свойства».
В Windows 10 откроется следующее окно:
Справа в окне выбираем опцию «Дополнительные параметры системы» и переходим на закладку «Дополнительно».
Выбираем раздел «Быстродействие» и жмем кнопку «Параметры», как показано на рисунке ниже:
В разделе «Виртуальная память» нажимаем кнопку «Изменить».
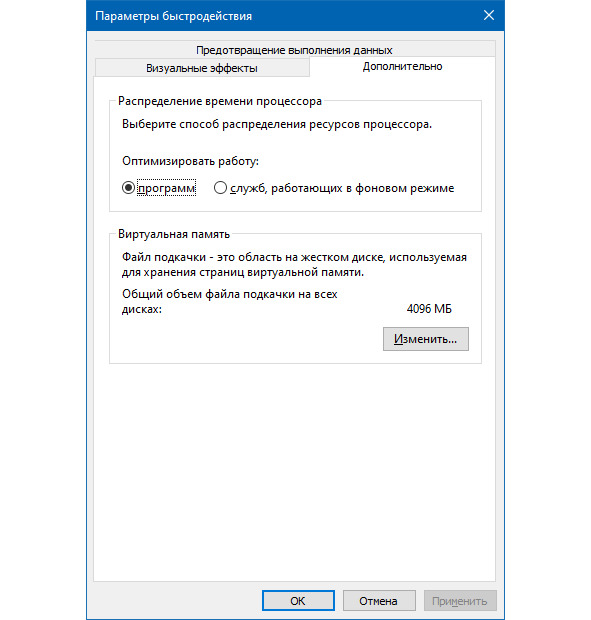
И ставим галочку на опции «Автоматически выбирать объем файла подкачки», как показано ниже:
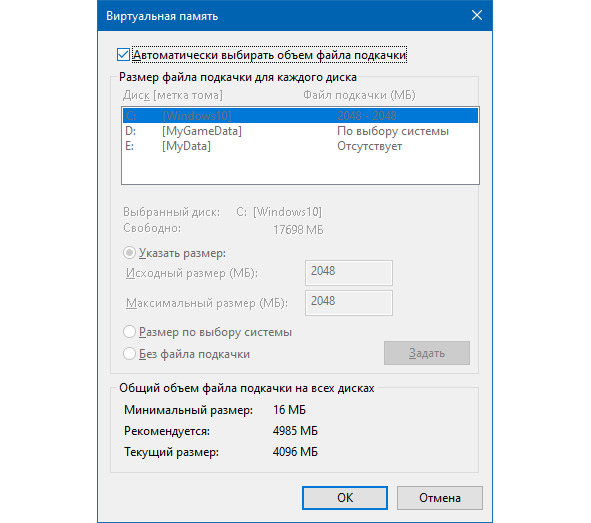
Теперь немного поясню, зачем мы это сделали.
Во-первых, если вы хотите, чтобы у вас все работало в системе и в играх быстро, то файл подкачки нужно делать фиксированного размера, ориентируясь на параметр «Рекомендуется».
Во-вторых, это не работает так же, если вы пользуетесь установленными на ваш компьютер системами генеративного искусственного интеллекта, которые пытаются выжать из вашего компьютера все возможные вычислительные ресурсы. Если ресурсов не хватит, то компьютер либо зависнет, либо вы увидите «синий экран смерти».
Поэтому экспериментальным путем было установлено, что файл подкачки нужно сделать автоматически изменяемым операционной системой.
И только теперь мы можем приступить к работе с Stable Diffusion WebUI Forge и FLUX.
Шаг 4. Первый запуск и тест моделей FLUX.1
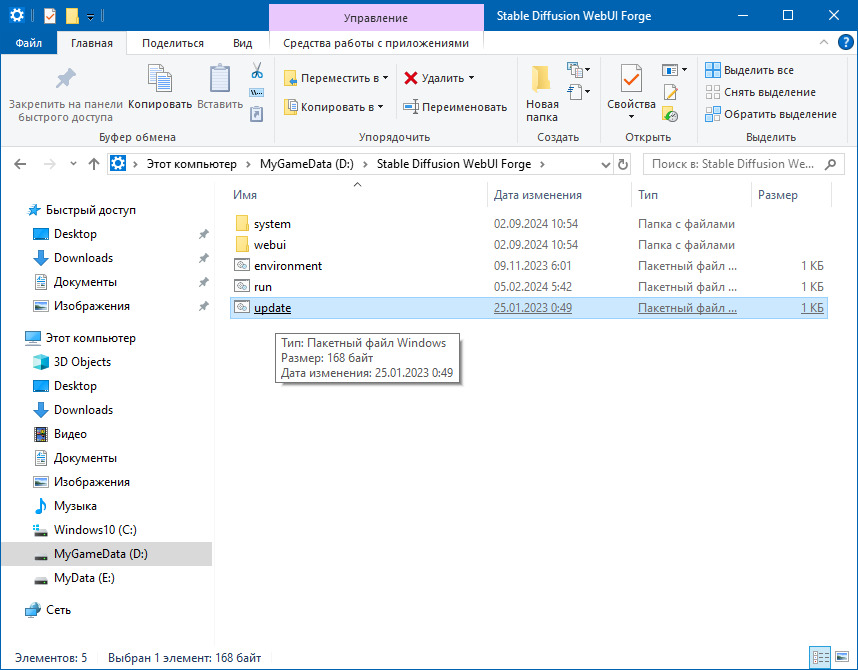
Казалось бы, нам нужно жать мышкой на файл run.bat, но, увы, это не так.
Давайте возьмем для себя за первое правило всегда запускать перед работой файл update.bat. Да, именно он позволит нам всегда использовать самую последнюю версию нашей сборки Stable Diffusion WebUI Forge.
Жмем мышкой на update.bat и наблюдаем за окном обновления, которое представлено ниже:
Когда все обновления будут скачаны и установлены, вы можете закрыть данное окно.
Чтобы приступить к работе с FLUX и запустить Stable Diffusion WebUI Forge, жмем на файл run.bat (всегда после update.bat).
Перед нами откроются два окна:
— Первое окно — это серверная часть программы. Закрывать его не нужно вплоть до окончания работы с системой. Оно будет открываться всегда, когда мы запускаем нашу программу.
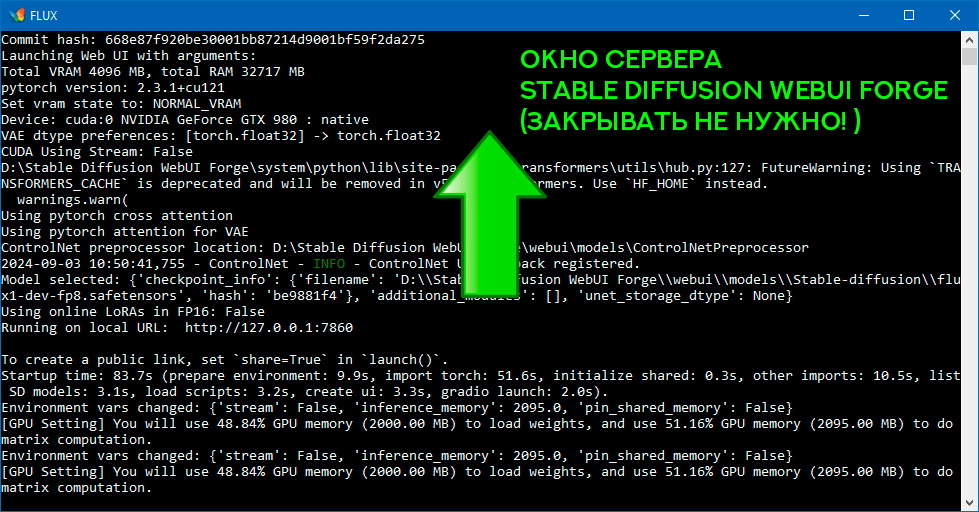
В этом окне отображается много важной информации, особенно при создании изображений. В нем в случае сбоя вы сможете также увидеть описание причины сбоя и много другой полезной технической информации.
— Второе окно, которое откроется в вашем интернет-браузере, — это окно пользовательского интерфейса программы Stable Diffusion WebUI Forge на английском языке.
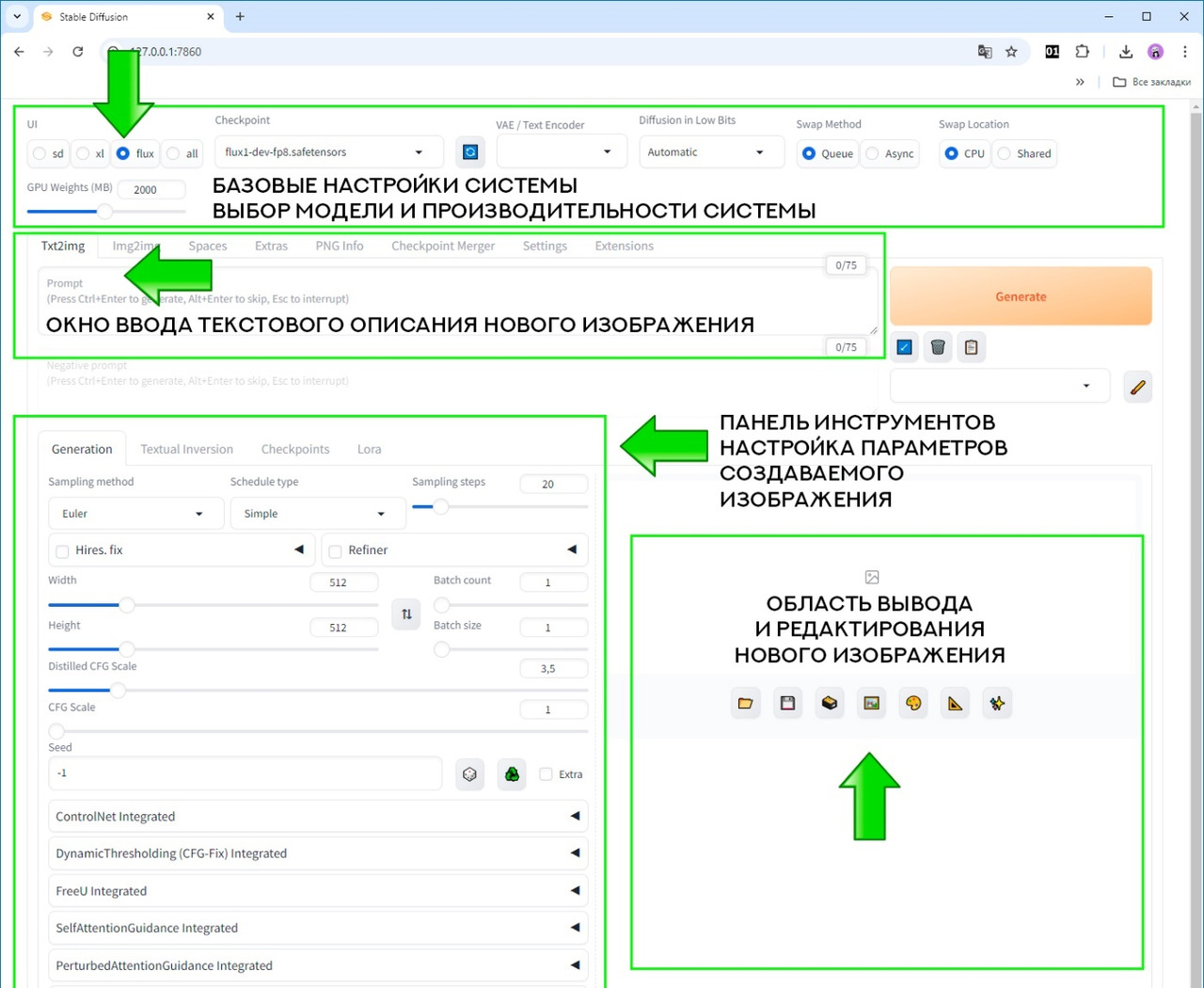
С этим окном мы будем с вами работать все свое основное время при создании и обработке новых изображений.
Прежде чем приступать к генерации нового изображения, нам с вами нужно обратить свое внимание на очень важный аспект работы системы генеративного искусственного интеллекта Stable Diffusion WebUI Forge, а именно на выборе модели и настройке производительности системы.
Все необходимые базовые параметры находятся сверху окна пользовательского интерфейса, как показано на рисунке ниже:

Рассмотрим их более подробно.
UI (пользовательский интерфейс) — это настройка предустановок (пресетов) пользовательского интерфейса, которая включает несколько опций выбора: sd; xl, flux и all. Как вы можете догадаться из их наименований, в зависимости от того, какую модель вы будете использовать, изменится вид пользовательского интерфейса и панели инструментов. Я рекомендую выбрать flux, так как это наша основная модель, которой мы посвятим 100% своего времени.
Checkpoint (контрольная точка) позволяет нам выбрать одну из установленных у нас моделей FLUX, при помощи которой мы будем создавать наши уникальные изображения. Я бы порекомендовал начинать эксперименты с модели flux1-schnell-bnb-nf4.safetensors, затем перейти к flux1-dev-fp8.safetensors. Эти модели менее требовательны к ресурсам компьютера и выдают вполне реалистичные изображения.
VAE / Text Encoder (настраиваемый вариационный автокодировщик). Эта опция позволяет использовать нам специальный автокодировщик, который помогает ускорить процесс создания и улучшить качество изображения. Для первого запуска он нам не нужен, да и у нас пока что нет соответствующего файла. Оставляем поле пустым.
Diffusion in Low Bits. Если у вас небольшой опыт с моделью или вы только учитесь, опцию не меняем и оставляем Automatic, в противном случае — при неправильном выборе вы можете потратить много дополнительного времени на генерацию изображения без гарантии того, что оно получится лучше, чем если бы мы оставили опцию по умолчанию Automatic.
Swap Method. Опция предлагает нам выбрать один из методов обработки (по очереди или асинхронный). Мы выбираем метод по очереди (Queue).
Swap Location. Мы выбираем CPU. Этот метод дает нам загрузку части модели в память графического ускорителя GPU (в память вашей видеокарты) и оставшуюся часть — в оперативную память компьютера CPU. Этот метод работает несколько медленнее, чем Shared, но надежнее (по утверждению разработчика).
Если мы выберем метод Shared (который работает несколько быстрее), то часть модели будет загружена в оперативную память GPU, а оставшаяся часть будет размещена в виртуальной оперативной памяти (или общей памяти GPU), которая резервируется для видеокарты из фактической оперативной памяти вашего компьютера.
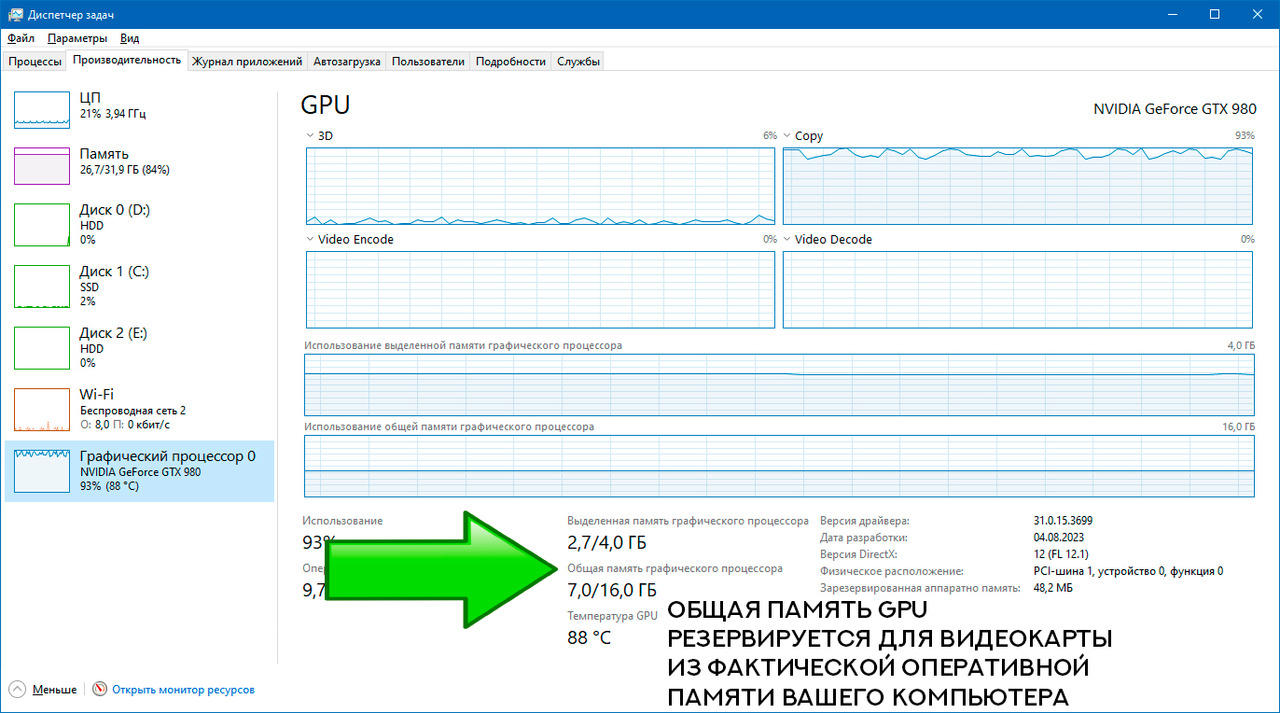
Разница методов заключается в том, что в первом случае вся оперативная память доступна центральному процессору и другим приложениям. Во втором случае зарезервированная оперативная память доступна только графическому процессору и не доступна другим приложениям. Другими словами, при выборе опции CPU вы можете продолжать рабату в Word или Photoshop в тот момент, пока создается ваше новое изображение.
Мои эксперименты показали, что влияние обоих параметров на производительность незначительное (плюс-минус десять секунд на генерацию нового изображения).
GPU Weights (MB) (вес графического процессора). Опция предлагает нам определить нагрузку на оперативную память графического процессора — GPU. Здесь нужно подбирать параметр экспериментально в каждом отдельном случае. Но опыт показывает, что при не очень мощных видеокартах лучше ползунок сдвинуть на середину. Даже если у вас очень мощная карта, ползунок нужно сдвинуть всего на две трети вправо, оставив одну треть памяти видеокарты незадействованной. В обоих случаях это позволит вам работать с пользовательским интерфейсом и другими программами (которые открыты у вас на компьютере) без зависаний и тормозов.
Например, для видеокарты NVIDIA GTX 980 с 4 Гбайтами видеопамяти я выделил на генерацию изображений всего 2 Гбайта памяти. Мало? Нет. У меня все модели прекрасно работают. В противном случае генерация не происходит или компьютер зависает.
На основе вышеизложенной информации вы теперь можете настроить наилучшую конфигурацию для своего устройства.
Теперь давайте посмотрим, насколько хорошо работают скачанные нами модели.
Для этого выполним следующие действия:
Выберем первую модель, с которой будем работать — flux1-schnell-bnb-nf4.safetensors.

Под меню выбора модели и базовых настроек находятся восемь закладок, каждая из которых дает доступ к различным функциональным интерфейсам программы Stable Diffusion WebUI Forge.
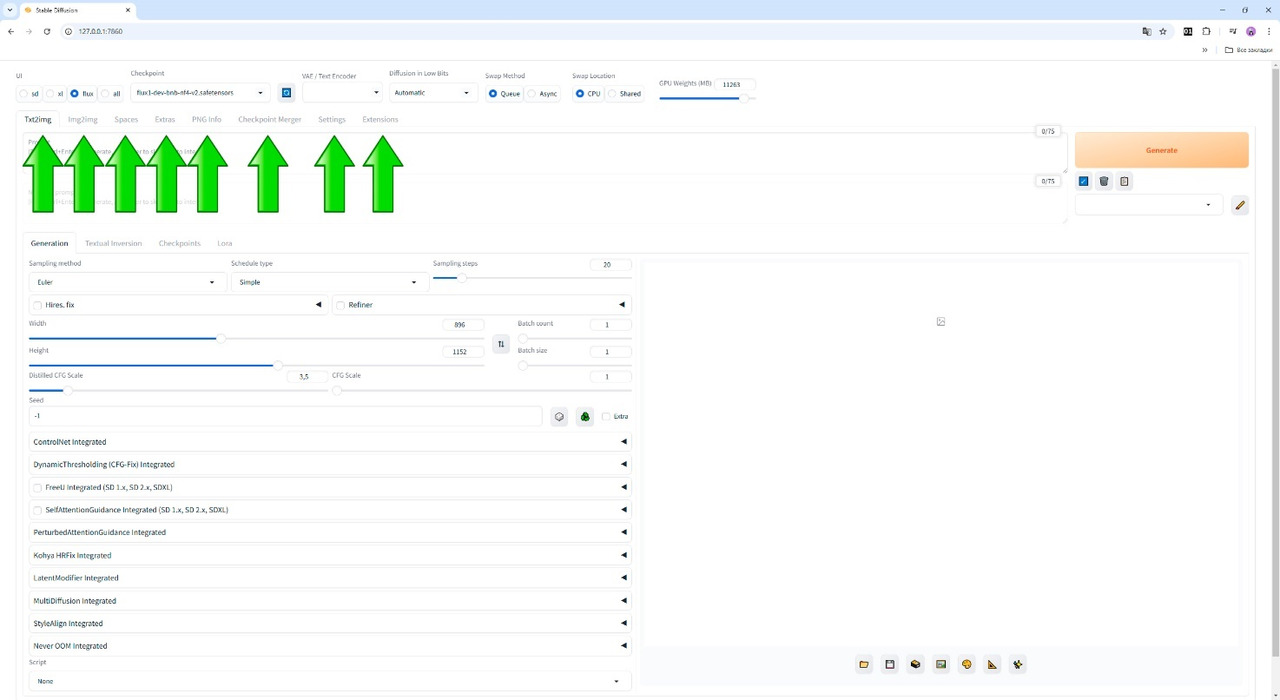
Давайте рассмотрим их подробнее:
— Закладка Txt2img открывает перед нами интерфейс с параметрами генерации и окном вывода нового изображения.
— Закладка Img2img — это интерфейс с параметрами генерации изображения из изображения и окном вывода нового изображения.
— Закладка Spaсes (пространства) — это интерфейс, который дает нам доступ к новым сервисам программы. Он позволяет нам установить сервисы (которые включают в том числе дополнительные модули и модели), запускать сервисы, работать с новыми интерфейсами сервисов, останавливать работу сервисов и удалять их из программы и с нашего компьютера. Работу с сервисами мы рассмотрим в отдельной главе.
— Закладка Extras (дополнения) — это интерфейс, который позволяет нам получить доступ к дополнительным возможностям Stable Diffusion WebUI Forge.
— Закладка PNG Info — это интерфейс, который позволяет получить перечень параметров из файлов изображений, которые мы будем создавать. Например, наш запрос, уникальный номер изображения и много другой информации.
— Закладка Checkpoint manager — это интерфейс, который позволяет собрать свою модель из нескольких имеющихся.
— Закладка Settings — это закладка с большим перечнем настроек Stable Diffusion WebUI Forge.
— Закладка Extantions — это закладка с перечнем установленных в Stable Diffusion WebUI Forge расширений. В этот список будут добавлены все сервисы, которые вы установите, воспользовавшись Закладкой Spaсes.
Подробнее закладки мы рассмотрим далее. Сейчас мы с вами перейдем на закладку Txt2img и будем пока что работать только с данным интерфейсом.
В окне ввода текстового описания добавим следующую тестовую фразу, которую приводит у себя на сайте разработчик: «Astronaut in a jungle, cold color palette, muted colors, very detailed, sharp focus».

Обратите, пожалуйста, свое внимание на то, что все описания изображений (которые вы хотите создать) делаются на английском языке. Если у вас есть какие-то сложности с переводом, вы можете воспользоваться переводчиком.
Далее в панели инструментов установим размер (разрешение) изображения, которое мы будем создавать на значения: Width (ширина) 512 и Height (высота) 512.
Все остальные параметры оставим без изменений и нажимаем кнопку Generate (Создать).
Модель flux1-schnell-bnb-nf4.safetensors
Поздравляю вас, спустя всего несколько минут мы с вами получаем наше первое изображение, созданное при помощи модель FLUX.1 [schnell] (загруженный файл flux1-schnell-bnb-nf4.safetensors).
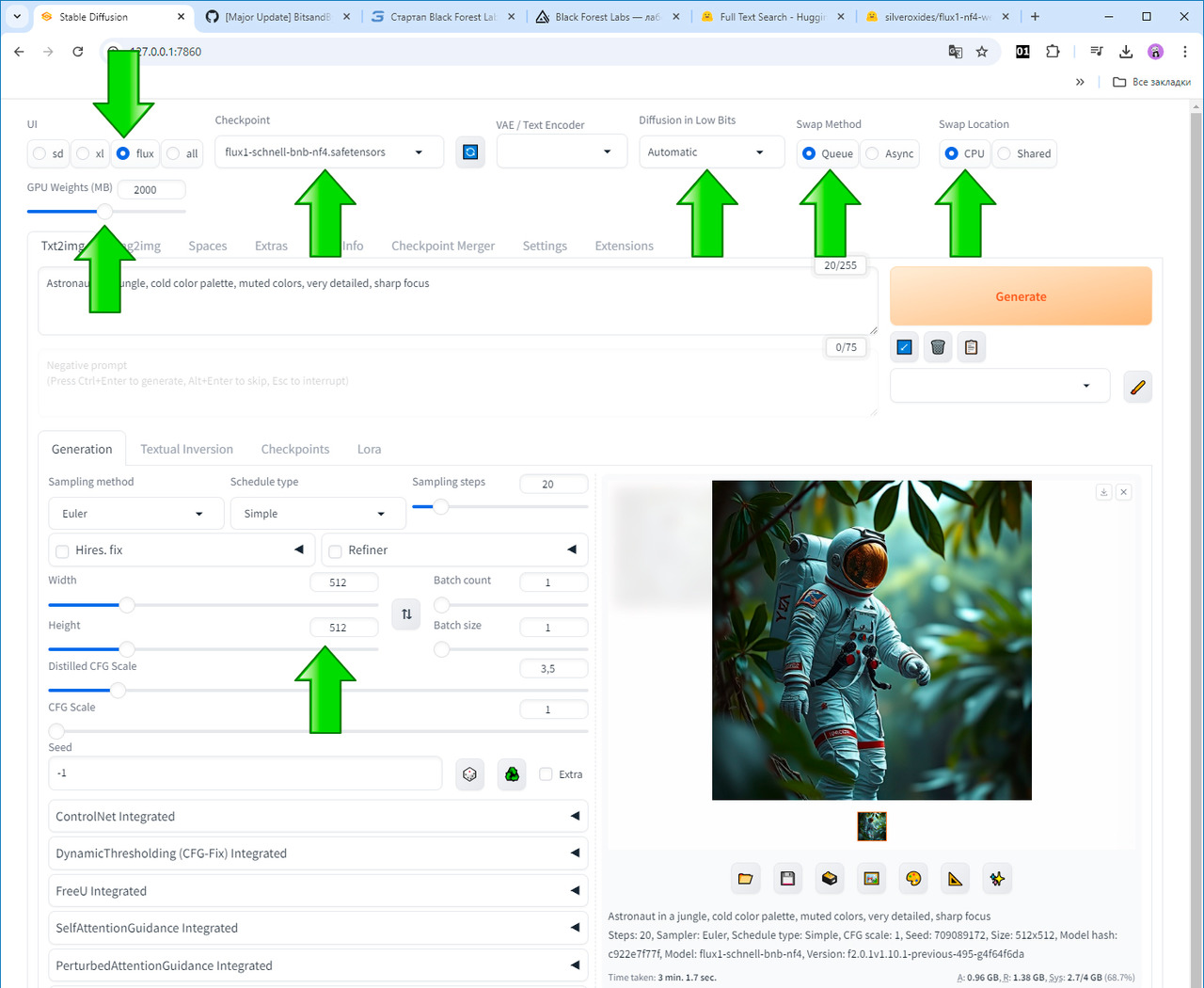
Изображение, которое мы получили, полностью соответствует примеру, который разработчик Stable Diffusion WebUI Forge приводит у себя на сайте. Это хорошо потому, что мы теперь с вами знаем, что модель работает правильно.
Обратите внимание на то, что у нас с вами из фразы «Astronaut in a jungle, cold color palette, muted colors, very detailed, sharp focus» могут получиться немного разные космонавты. Это не страшно. Важно, чтобы они были в целом похожи как по стилю, так и по содержанию запроса.
Модель flux1-dev-bnb-nf4.safetensors
Теперь давайте выберем другую модель flux1-dev-bnb-nf4.safetensors.

Все остальные параметры оставляем без изменений и нажимаем кнопку Generate (Создать).
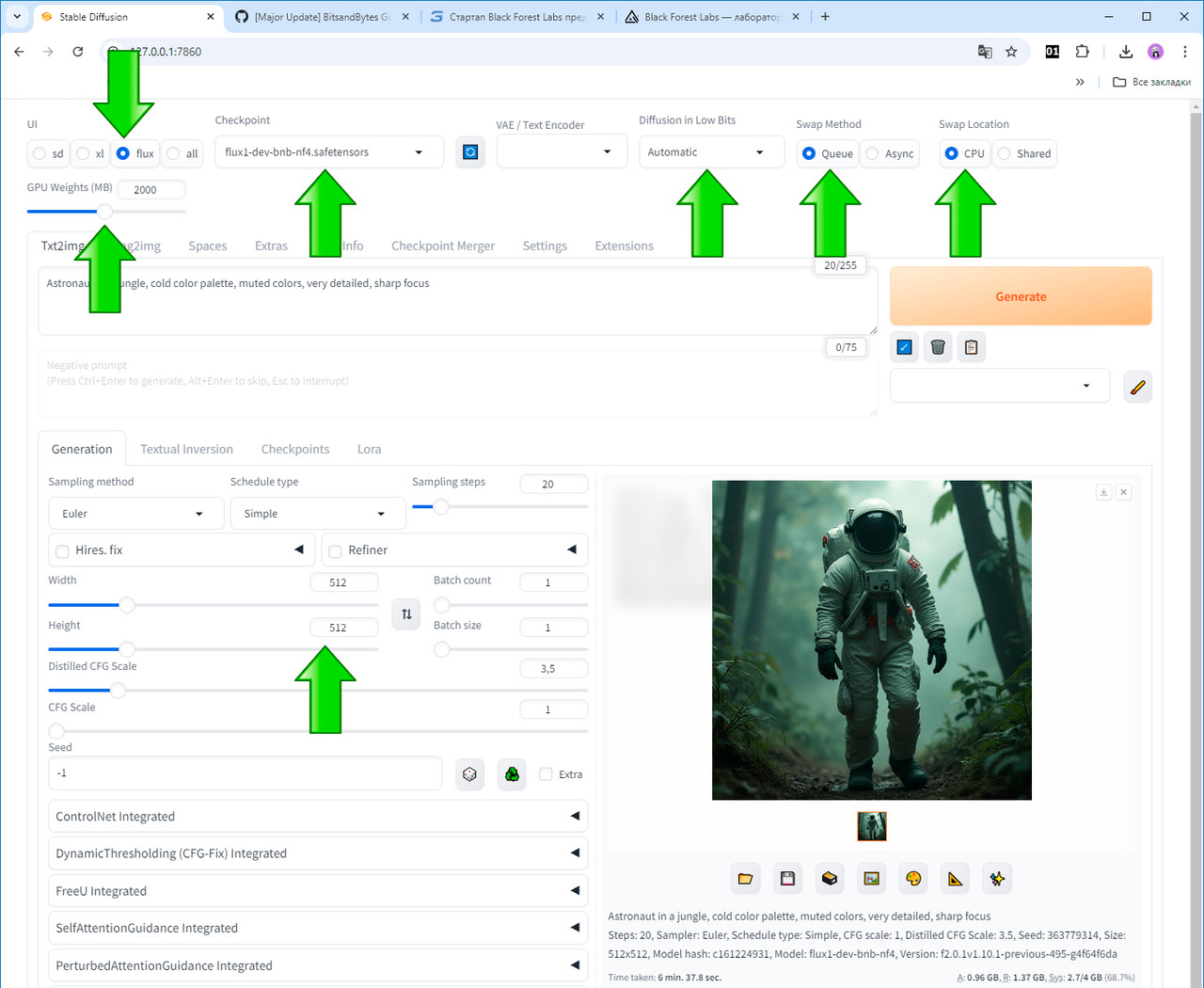
Мы с вами получили изображение, которое соответствует нашему описанию, что является подтверждением тому, что модель flux1-dev-bnb-nf4.safetensors работает на нашем компьютере без сбоев и мы можем ее использовать далее.
Далее мы проделаем все то же самое для других моделей.
Модель flux1-dev-bnb-nf4-v2.safetensors
Опять меняем Checkpoint на модель flux1-dev-bnb-nf4-v2.safetensors.
Бесплатный фрагмент закончился.
Купите книгу, чтобы продолжить чтение.